引言
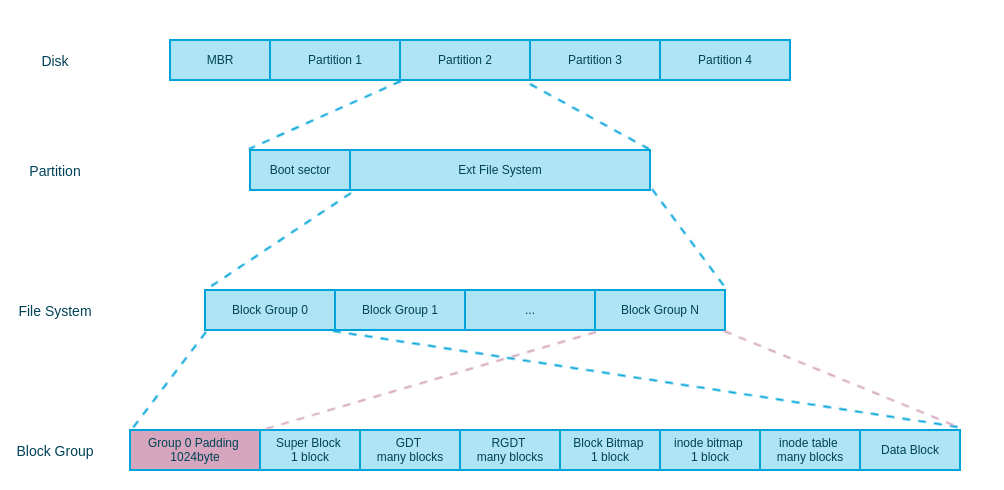
计算机处理数据无外乎是两种方式,一种是查询,第二种是修改。本文主要讨论的是查询这一操作,在查询数据时,我们最容易想到的方式那就是顺序查找,就遍历一遍呗,直到找到匹配的数据,那么时间复杂度是$O(n)$,当数据规模不大时,这么查找也没啥问题,但是一旦数据规模较大时,那么查询的时间就会变得很慢。这时候就有一些高效算法出来了,比如hash、内存中二分查找、存储引擎中的B+Tree,本文就详细介绍一下这些算法
最近忙着找工作,都没时间更新,今天忽然有点想法,想写一篇关于缓存的文章,仅仅是自己的一点看法。
如果说到缓存,大家可能会想到CPU的高速缓存、Redis、MemCached,还有自己实现的单机本地缓存,它们的作用其实都是一个,那就是方便我们的应用可以更快的获得我们需要的数据。
在远古计算机时代,计算机CPU的速度很慢,存储设备的速度也很慢,所以这个时候我们可能都用不上缓存,因为没必要嘛,CPU速度和存储设备的速度一致。
随着技术的发展,CPU由晶体管发展成超大规模集成电路使得cpu的发展发生了质变,cpu的速度越来越快。而存储设备虽然也有快速的发展,但是在速度上却没有质变。这里我们做一个假设,如果存储器设备的速度跟的上CPU的运行速度,那我们还需要缓存吗?当然不需要,因为如果速度还是一致的,那肯定是CPU直接访问存储设备,这样的架构是简单的架构。但是事实却不是这样,至少目前不是这样,当然不排除未来有什么特殊材料实现的存储设备拥有和cpu匹配的速度。因此从计算机的发展来看,缓存是为了存储设备的速度能够匹配CPU速度的一种折中方案。因为出现了内存,后来的CPU缓存,更后来的CPU多级缓存,它们的速度都是越来越快,当然容量也越来越小。
上一篇文章讲了分布式同步网络算法中的BFS、最短路径、MST和MIS算法,这一篇文章将会将分布式系统中一个非常重要的问题-一致性。在单节点的环境中,一致性问题是比较容易解决的,像单节点的数据库,因为只有一个节点,也就不存在数据不一致的说法。
因为机器总会有概率出故障,如果仅仅是单节点应用,一旦机器发生故障,那么服务将不可用。为了提供高可用的应用,多节点部署应用成为一种解决方案,但是多节点部署应用也引发了一些问题,比如节点故障依然存在;并且因为多节点,导致节点间需要通信,因此系统存在通信故障,如果机器不是在自己机房内,可能要有Byzantine故障,这些问题都可能导致数据一致性问题。比如,在分布式数据库事务中,假设两个进程a,b需要通信来达成是一致(提交或者回滚),因为通信故障,a收到b的提交请求,但是b没有收到a的请求,此时a可能会提交,而b可能回滚,那么就出现数据不一致。
接下来的文章的结构是,第一部分是介绍在分布式同步网络中,如何在通信故障下解决一致性问题;第二部分介绍,如何在节点停止故障下解决一致性问题;第三部分介绍,如何在节点出现Byzantine故障下解决一致性问题。
在前一篇文章概述中,提到了分布式系统模型大致分类为同步网络模型、异步共享存储器模型、异步网络模型和部分同步模型。今天开始,将慢慢介绍同步网络模型的一些算法,因为同步网络模型有一些严格的环境假设,所以同步网络模型算法比较简单,但是同步网络模型是一个理想化模型,现实生活中这种模型是非常少的,但是学习它们也有助于我们理解后边的异步模型算法和部分同步模型,在接下来的几篇文章中,将分别介绍分布式领域中比较热门的话题包括Leader选举、一致性(包括著名的Byzantine故障下的一致性)、最小生成树和最短路径等问题
先从Leader选举开始
随着互联网的发展和业务的复杂度提升,越来越多的应用开始使用微服务架构,因此对于学习分布式基础知识非常有必要。因为我们平时做开发可以熟练的使用工具,但是有时候不知道其背后的原理会让人很不爽。
提到分布式系统,可能很多人就会觉得那是很多机器,当然这个没错,但是我们不应该以机器的数量来分辨是不是分布式系统,当然多机器肯定是分布式,但是单机就一定不是分布式系统吗?答案肯定是不一定,在NancyA.Lynch的《分布式算法》一书中,都是用抽象为”进程”理解的,如果我们用机器来理解,假设公司分配的机器是8核16G,那你肯定不会只部署一个服务,肯定会部署多个服务,这些服务之间可能相互调用,那么它们就是一个分布式系统。
2017年正直互联网金融崛起之时,由于那时候监管不规范,互联网金融公司如雨后春笋般崛起,我也是这时入职了一家互联网金融创业公司(一个大集团的全资子公司)。入职之前可能因为公司没有技术团队来开发一套完整的贷款系统,因此外包了系统给一个外包公司(这里就不说是哪家了),整个项目软件技术偏老,JDK当时还是用的1.7,外包系统可能大家都懂的,它们为了批量生产,基本都是有一个自有框架,然后在其框架上做开发。维护过外包系统的人可能都知道,那是一个非常痛苦的,就拿我接手的这个项目来说吧,我主要列几点。
出于这些原因,核心团队立志要将这个庞然大物重构,由于当时流行微服务,因此决定采用微服务的方式拆分。因为大家这个时候经验都不丰富,技术团队几乎没有任何积累。做起来,真的困难重重。我们重构主要分为3个阶段,第一阶段,稳定系统;第二阶段,自动化发布;第三阶段,微服务化
上一篇学习了文件系统的原理,我们知道了操作系统是如何管理文件的,但是却没有学习磁盘是如何处理操作系统发出的读写操作,这一篇我们要学习操作系统是如果实现I/O和管理I/O的。
I/O包含两部分,I/O设备和I/O接口以及如何管理I/O设备,I/O设备就是我们常见的磁盘、网卡、鼠标键盘、打印机和显示器等。
接下来的文章就要学习I/O设备、I/O模型和I/O、中断处理和错误处理。
设备控制器有一个寄存器用于和CPU交互,有一些控制器还有数据缓存结构,接下来要讲讲如何解决CPU和设备控制器寄存器和数据缓存交流的方式