概述
之前介绍过一篇IO总览的文章,概述性的讲解了现有的一些Java IO。从这一篇开始,详细讲解Java IO的各个模块,今天首先讲一下InputStream。
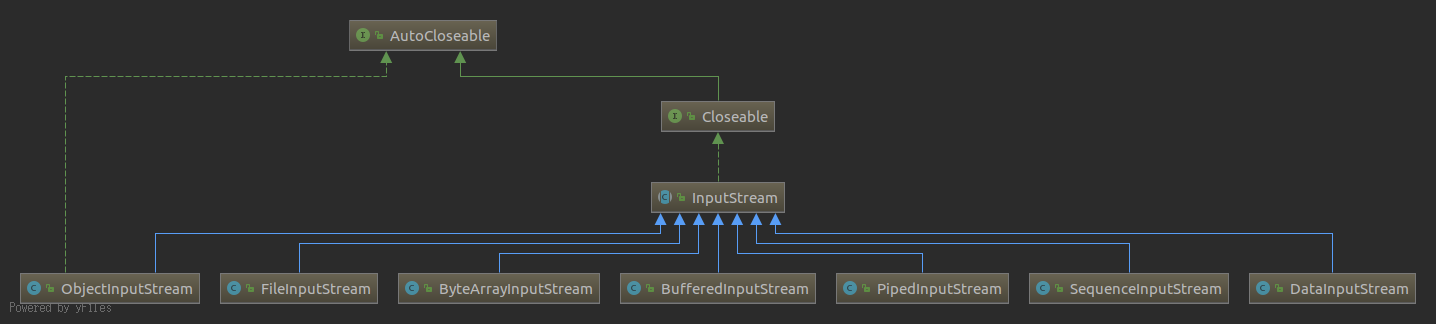
InputStream是一个字节输入流,什么是字节流呢?我们知道在java中有一个叫byte的基本类型,就是同一个。字节是一个8位表示的二进制。很多人会误认为输入流就是打开一个磁盘文件然后从里边读数据,但是输入流并不局限于文件,应该说IO并不代表和磁盘交互。所以读取磁盘文件仅仅是输入流中的一种FileInputStream,在输入流中还有很多其他的输入流。接下会介绍几种,虽然有些不常用。在介绍之前先看一下在JDK中,InputStream的继承关系:
AutoCloseable
这里的AutoCloseable是jdk1.7引入的一种语法糖,可配合jdk1.7出现的try-with-resources新语法特性一起使用,用于在使用完资源后自动关闭。Closeable是表示这是一个可关闭的数据源或目标。
1 | public class AutoCloseableDemo { |
节点流
什么是节点流呢?节点流指可以从一个数据源读写数据,这个数据源可以是磁盘文件,内存或者网络。根据这个定义可以将上图中的流FileInputStream、PipedInputStream、ByteArrayInputStream划分为节点流。最熟悉的可能就是FileInputStream,因为平时读取磁盘文件应该用得最多,先介绍FileInputStream。
FileInputStream
看一下该类的构造函数
1 | //参数:文件路径 |
通过jdk api文档可以看到FileInputStream有三个构造函数,第一个和第二个比较常用,第三个是一个已存在的文件系统的真实连接。
1 | public class FileInputStreamDemo { |
ByteArrayInputStream
ByteArrayInputStream比较少见,ByteArrayInputStream内部维护着一个缓冲区,从该缓冲区中读取字节,内部计数器跟踪read要读取的下一个字节。看一下构造函数:
1 | ByteArrayInputStream(byte[] buf); |
可以看到ByteArrayInputStream以byte数组为参数构造ByteArrayInputStream对象。ByteArrayInputStream和FileInputStream的区别在于,FileInputStream以磁盘文件为数据源,ByteArrayInputStream以内存数据为数据源。ByteArrayInputStream的用法:
1 | public class ByteArrayInputStreamDemo { |
结果:
1 | Connected to the target VM, address: '127.0.0.1:38135', transport: 'socket' |
从结果中看到虽然bytes有5个数据,但是只能读取2个数据,因为在构造时传入了offset和length表示从offset开始的length个数据。至于ByteArrayInputStream的内部实现细节,在以后的进阶文章中再详细论述。
PipedInputStream
PipedInputStream是一种很特殊的输入流,因为它单独存在没有什么意义,它需要和PipedOutputStream一起使用,数据的流向是从PipedOutputStream流向PipedInputStream的缓存区,然后PipedInputStream的read方法从PipedInputStream的缓冲区中读取数据。如下图
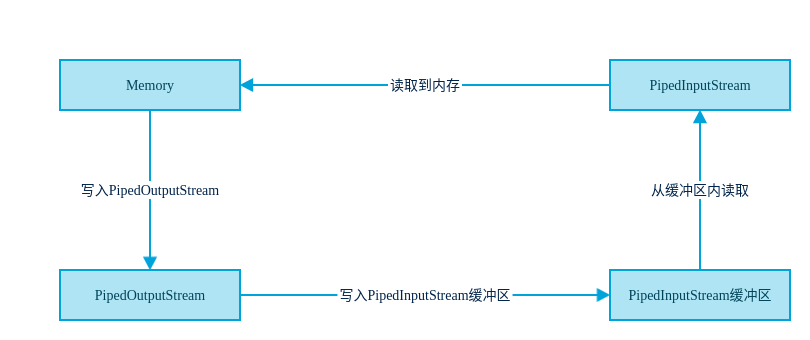
接下来看一下使用PipedInputStream来实现一个简单线程通信例子,当然线程通信有其他方式来实现,但是如果两个线程之间需要传递字节数组时,PipedInputStream还是不错的选择。
1 | public class PipedInputStreamDemo { |
处理流
什么又是处理流呢?处理流是连接在已存在的流(节点流或者处理流)之上,通过对数据的处理提供更强大的读写功能。在InputStream中有如下几种处理流,BufferedInputStream、DataInputStream、ObjectInputStream、SequenceInputStream。接下来简单介绍一下几种流。
BufferedInputStream
BufferedInputStream是一个处理流,它的作用是增强InputStream,为其提供缓冲区的功能。这里可能会有疑问,BufferedInputStream实现的方法和InputStream的方法差不多,它存在的意义是什么?
这里要从Java IO读取数据的过程说起,仅仅简单的介绍一下,InputStream读取数据源的数据需要操作系统支持,也就是说Java的线程发出读取数据(read方法)的请求,操作系统接收到这个请求,然后从数据源读取一个byte(read方法,不是read(byte[])),然后将数据从内核空间复制到用户空间,java线程拿到要的数据,返回。可以看到,如果调用read()方法,那么读取10个字节,就要进行10个这样的流程,是相当低效的,当然可以用read(byte[]),但是有时需要read()的场景,所以就出现了InputStream的增强类BufferedInputStream,该BufferedInputStream提供了缓存区的功能。
举个例子,以前你要把一堆砖从一个地方搬到另一个地方整理好,你力气小一次只能搬一块,当然别人可能力气大,一次可以搬两块,这样你搬10块砖要来回跑10次,那现在为了增强你的能力,给你提供一个小车,你一次可以运50块,这个时候你只需要一次就可以运50块砖,而你要整理好这些砖,只需要从小车上一次一块拿下来放好,就像从缓冲区里读取数据一样。通过提供缓冲区来增强IO的能力,减小系统开销。
简单使用
1 | public void readDemo(String path){ |
DataInputStream
DataInputStream提供了从字节输入流中读取Java基本类型的能力,比如,如果要想从输入流中读取一个int类型的数据,需要读取4个字节然后自己组装成一个int,而DataInputStream通过提供一个InputStream的装饰器,增加了自动包装的功能。
简单使用
1 | public class DataInputStreamDemo { |
打开文件test1看到的结果,如果以字节流读取出来,将两两字节组合转换为char便可以还原。DataInputStream提供的就是这种功能,此外还有readInt()、readLong()、readFloat()等,比较特殊一点的readUTF(),readUTF是转化成utf-8编码格式的,用readUTF()读,那么你写的时候也要用writeUTF()写,writeUTF在写时会在开头写两个字节表示写入的数据大小。readUTF时会首先读取这两个字节,来设置读取的字节数。
1 | ^@h^@e^@l^@l^@o^@ ^@w^@o^@r^@l^@d |
读取结果:
1 | Connected to the target VM, address: '127.0.0.1:44515', transport: 'socket' |
ObjectInputStream
ObjectInputStream是java提供的反序列化的功能,ObjectOutputStream提供序列化输出的功能,能将java对象序列化之后输出到指定的输出流中。被持久化的对象需要实现Serializable、Externalizable接口。
1 | public class ObjectOutputStreamDemo { |
SequenceInputStream
SequenceInputStream的作用是将多个输入流合并为一个SequenceInputStream输入流,然后从第一个输入流开始读取数据,接着第二个,直到最后一个。
1 | public class SequenceInputStreamDemo { |