背景
从一个问题说起,前几天在和一家公司做项目对接时,我方公司提供给对方的是返回的code码作为成功还是失败校验,对方公司因为使用了我方返回的msg作为组合校验,而返回msg出现乱码,导致对方公司作字符串匹配时失败,以为我方返回的是失败。这时,对方公司截图发给我方要求我方检查编码。我虽不才,但是我方使用的编码我还是可以保证的,我敢大声的说不是我方的问题。为此开启了一条甩锅之路(不对啊,明明不是我的锅,为什么要叫甩锅)。
这时,我开始找证据,首先我得搞清楚那句乱码正常应该是什么信息,我看到该请求在执行数据查询时抛了一个RuntimeException,这个会交给全局异常处理器处理,然后找到了本来该返回的信息“内部系统错误,请联系管理员”这一句,总共13个中文字符,这时我在看了一下对方截图的乱码如下图所示,我数了一下总共39个乱码字符,哈哈,这个字数符和我方UTF-8的编码编码13个中文字符的字节数刚刚吻合,这个时候已经可以甩掉这个锅,但是我决定帮对方找到他们错误使用的编码,这时浮现在我脑海中单字节编码集ISO-8859-1和ASCII。

接下来我要帮对方找到问题的原因,写了一段测试代码
1 | public class EncodeTest { |
iso-8859-1的输出
1 | ç³»ç»å é¨é误ï¼è¯·è系管çå |
ASCII的输出
1 | ��������������������������������������� |
完美,这下可以确定对方在解码我方返回结果时采用的是什么编码了,就是ASCII码。眼尖的朋友可能看到了为什么图片里还有其他正常的中文,如果有这个疑问,看完后边的解析后应该能够明白。
编码集
单字节编码
ASCII
ASCII是现今最通用的单字节编码系统,使用7位二进制数来表示所有的字母、数字、标点符号及一些特殊控制字符,作为美国编码标准来使用。ASCII定义了128个字符,包括33个不可打印的控制字符(non-printing control characters)和95个可打印的字符。
ISO-8859-1
ISO-8859-1是单字节编码,又称Latin-1,用8为编码,向下兼容ASCII,是许多欧洲国家使用的编码标准。其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
多字节编码
单字节编码在使用英文的国家可以满足需求,可是对于其他国家的文字则不能用单字节编码,比如我们使用的中文。因为ISO-8859-1使用8位编码,最多也只能表示256个字符,而世界上其他国家的文字,单是我们使用的中文就远远不止256。
GB2312
gb2312使用两个字节(或一个字节,半角字符)编码,分为高位和低位,规定当字节值小于127时和ASCII码相同,如果两个大于127的字节连着时,就表示中文字符,此外这些编码里,还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
GBK
即使GB2312可以编码7000多个字符,但是还是不够,于是又进一步规定两个字节中的低位不一定要大于127,只要高位大于127就表示一个中文字符。通过这样扩展就增加了20000多个中文字符,其中包括繁体字。
GB18030
扩展了GBK,增加了少数名族字符。
UNICODE
由于各个国家都这样自己搞了一套编码,导致非常不通用,ISO解决了这个问题,废弃了其他国家或地区的编码,制定了一套国际通用的编码,该编码强制用两个字节来表示任何字符,包括ASCII中的半角字符也是两字节编码,UNICODE可以表示65535个不同字符。
UTF
由于网络的兴起,UNICODE由于必须由两个字节表示,在网络传输中那些半角字符会浪费带宽,所以UNICODE在网络中如何传输就成为一个问题,这时出现各种UTF标准,UTF-8就是每次8位传输数据,UTF-16则一次传输16位。UTF-8编码从1-6字节,编码常用汉字用3个字节。
例子
现在举个例子,我们以“你好啊,Ikan!”为例子,分别看一下将它编码成ISO-8859-1、GBK、UTF-8,所占的字节数和字节数组的值是否与上一小节描述相符。
ISO-8859-1编码解码
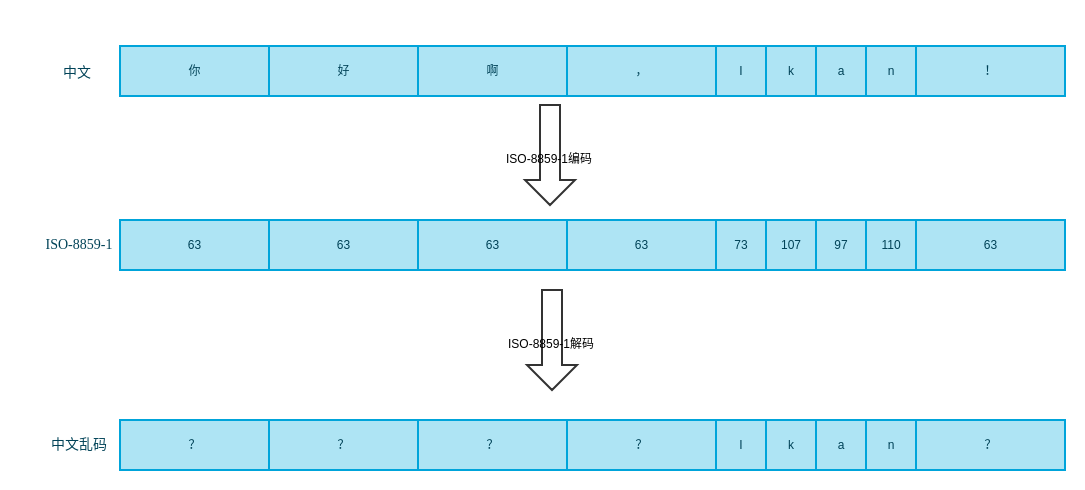
从图中看到,用ISO编码中文,因为找不到对应的编码,全部被编码为了63,所以就出现大家很熟悉的乱码。
GBK编码解码
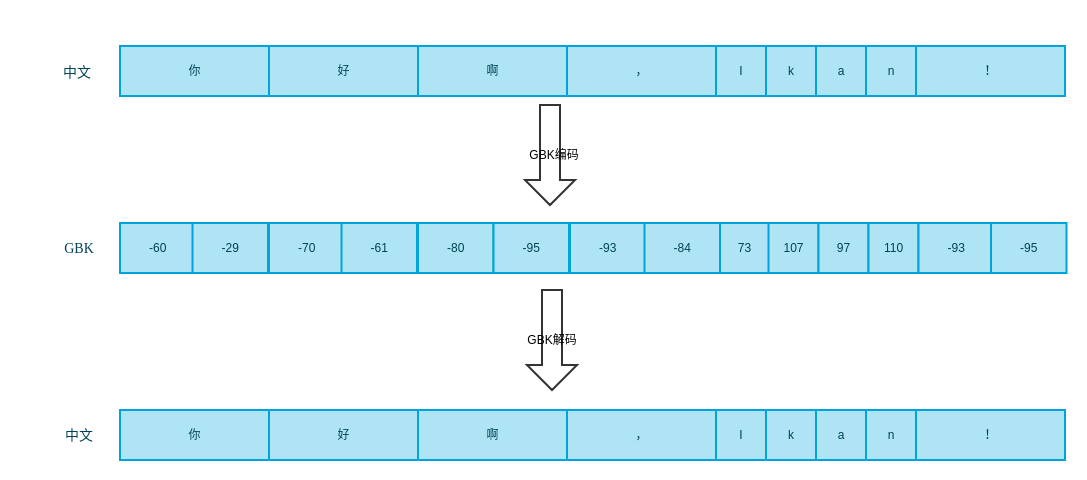
GBK用两个字节编码中文字符,用一个字节编码ASCII字符。
UTF-8编码解码
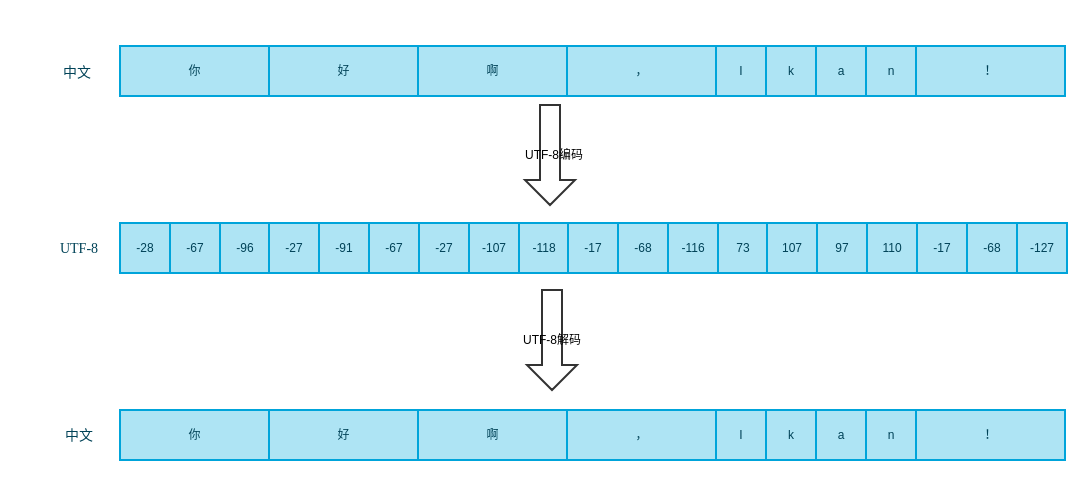
UTF-8用3个字节编码中文字符,用一个字节编码ASCII字符。具体是怎么表示的呢?UTF-8规定,字节以0开头表示后面7位表示一个ASCII字符,如果以10开头表示这个字节后6位表示字符的部分内容,如果以110\1110\11110…表示这是一个起始字符有多少个1就表示这个字符有多少个字节。
乱码产生的原因
通过上面的分析,可以知道,乱码产生的原因
用ASCII或ISO-8859-1编码中文,导致信息丢失,无法还原。
编码和解码用的不是同一种编码,比如用GBK解UTF-8的编码
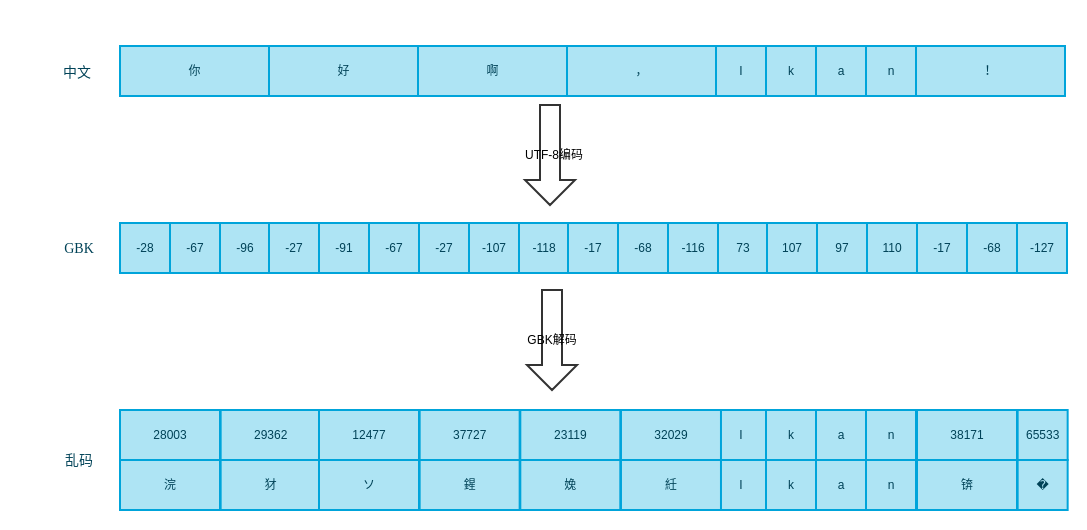
从上图看到中文字符串的前四个字符编码为12个字节,而GBK用2个字节编码中文,所以产生了6个中文字符,因为编码不一致,导致不能得到正确的中文。由此得到一个规律,当原始字符串中有中文时,gbk解utf-8编码的字符将得到比原始字符串多的乱码字符串,同理iso-8859-1和ASCII码。
Java中的编码
Java内编码
Java的内编码指JVM运行时是如何表示字符,Java的内编码用UTF-16,UTF-16即用两个字节来编码字符。大家可能对Java的编码系统有疑惑,或者经常Java运行时乱码搞不清楚,看一张图,来理一下Java从编辑java文件到编译然后在到JVM加载运行到传输过程中字符的表示方式以及转换过程。
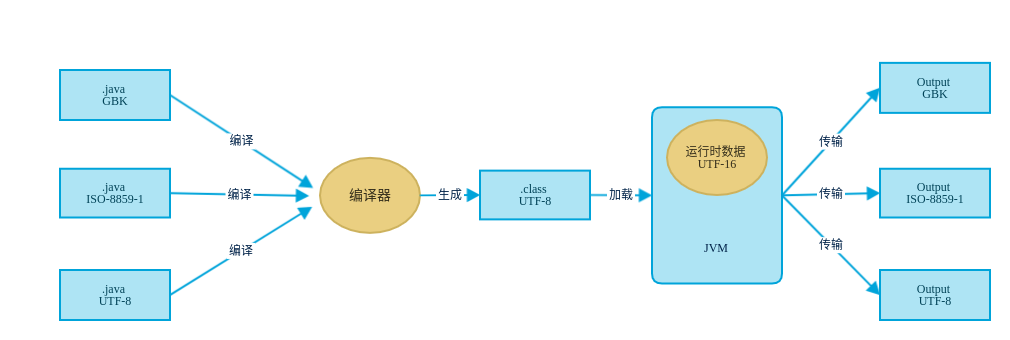
上图中我们看到不管你编辑.java文件时用的是什么编码,这就是我们可能经常用ide编辑代码时project是UTF-8这个时候ide在编译时是按UTF-8来编码,如果这个时候不知你从哪里复制过来一个.java文件,这个文件是GBK编码的,刚好这个文件里又有中文,这个时候如果编译,那么这个文件中的中文在程序运行产生结果传输时就会变乱码。在编译时都会被转换为UTF-8表示的.class文件(注意:在编译时如果没有指定.java文件编码,会采用系统本地编码格式),然后被加载到内存中时,我们知道在运行时,String内部其实是char数组,而我们知道一个char由两个byte组成,所以在运行时字符是UTF-16表示。至于如果传输程序结果,这个可以有多种编码方式,看程序如何指定。这个涉及到字符集和编码解码,接下来详细介绍这些部分。
CharsetEncoder(编码器)
CharsetEncoder构造方法
1
2
3protected CharsetEncoder(Charset cs, float averageBytesPerChar, float maxBytesPerChar)
protected CharsetEncoder(Charset cs, float averageBytesPerChar, float maxBytesPerChar, byte[] replacement)通过两个构造函数的修饰符,可以知道CharsetEncoder的构造函数是受保护的,设计者不希望用户直接构造该对象,如果用户要使用该对象那么就要通过Charset的newEncoder方法获取到CharsetEncoder对象,或者是通过继承CharsetEncoder来构造。
CharsetEncoder方法
CharsetEncoder方法较多,感兴趣的可以从这里去查看详细的介绍。
CharsetDecoder(解码器)
CharsetDecoder和CharsetEncoder类似,不啰嗦了,感兴趣的可以通过这里获得详细介绍。
CharSet(字符集)
Java支持的字符集很广泛,CharSet是所有字符集的父类。这里列几个常用的字符集和CharSet的继承关系图
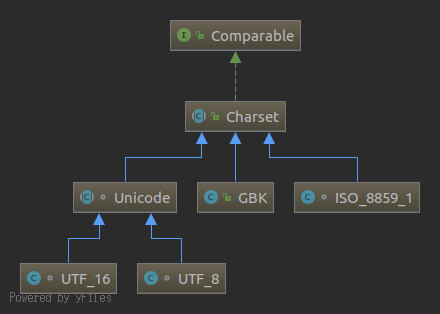
Charset是一个抽象类,本身是不能实例化的。
Charset方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39Set<String> aliases()
static SortedMap<String,Charset> availableCharsets()
boolean canEncode()
//和传入的字符集比较
int compareTo(Charset that)
//
abstract boolean contains(Charset cs)
//重要方法,传入byte缓冲以该字符集编码方式解码
CharBuffer decode(ByteBuffer bb)
static Charset defaultCharset()
String displayName()
String displayName(Locale locale)
//重要方法,传入字符串以该字符集编码方式编码
ByteBuffer encode(String str)
//重要方法,传入字符缓冲以该字符集编码方式编码
ByteBuffer encode(CharBuffer cb)
boolean equals(Object ob)
static Charset forName(String charsetName)
int hashCode()
boolean isRegistered()
static boolean isSupported(String charsetName)
String name()
//创建一个解码器
abstract CharsetDecoder newDecoder()
//创建一个编码器
abstract CharsetEncoder newEncoder()
String toString()简单例子
1
2
3
4
5
6
7
8
9
10public static void main(String[] args) {
Charset charset = Charset.forName("UTF-8");
ByteBuffer byteBuffer = charset.encode("你好啊,Ikan!");
for (int i=0; i<byteBuffer.array().length; i++){
System.out.print(byteBuffer.array()[i]);
}
System.out.println();
System.out.println(charset.decode(ByteBuffer.wrap(byteBuffer.array())));
}输出结果:
1
2-28 -67 -96 -27 -91 -67 -27 -107 -118 -17 -68 -116 73 107 97 110 -17 -68 -127
你好啊,Ikan!和我们前边的UTF-8编码一样。