认识Hadoop
简单描述,Hadoop是一款实现分布式海量数据存储和离线海量数据分析的工具。官方地址。Hadoop提供的安装方式有单机模式、伪分布式模式和完全分布式模式,不知道为什么有强迫症似的,如果有分布式模式必须要安装完全分布式模式。为了部署完全分布式模式的Hadoop,我采用docker的方式部署3个容器。不得不说docker确实是一个非常适合个人学习的安装各种软件的工具,如果你是windows环境,docker可以让你很方便的安装一个软件在Linux系统上。
准备和部署
环境选择
- 宿主机系统:win10
- hadoop版本:3.1.0
- 容器系统:ubuntu16
- jdk:1.8
安装包准备
由于我的网络原因,我选择预先下载好jdk和hadoop在本地然后用docker来构建Hadoop镜像。jdk下载地址这里我选择的是Linux x64的压缩包,因为我的镜像以ubuntu16为基础镜像,然后Hadoop下载地址。然后将文件和DockerFile一起。
配置文件准备
配置core-site.xml
1
2
3
4
5
6
7
8<?xml version="1.0"?>
<configuration>
<property>
<!--指定namenode-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
</configuration>配置hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<?xml version="1.0"?>
<configuration>
<property>
<!--指定namenode存放位置-->
<name>dfs.namenode.name.dir</name>
<value>file:///root/hdfs/namenode</value>
<description>NameNode directory for namespace and transaction logs storage.</description>
</property>
<property>
<!--指定hdfs datanode存放位置-->
<name>dfs.datanode.data.dir</name>
<value>file:///root/hdfs/datanode</value>
<description>DataNode directory</description>
</property>
<property>
<!--指定hdfs保存数据的副本数量-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>mapred.xml
1
2
3
4
5
6
7
8<?xml version="1.0"?>
<configuration>
<property>
<!--配置hadoop(Map/Reduce)运行在YARN上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<?xml version="1.0"?>
<configuration>
<property>
<!--nomenodeManager获取数据的方式是shuffle-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--指定Yarn的老大(ResourceManager)的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
</configuration>配置Hadoop启动环境变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-se-8u40-ri/
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
Dockerfile文件准备
1 | FROM ubuntu:16.04 |
文件结构
构建镜像
1 | # 切换到上图的文件目录 |
创建自定义子网
创建自定义docker子网来部署hadoop节点
1 | docker network create –subnet 172.19.0.1/16 hadoop |
配置系统路由
hadoop读写都是客户端直连数据节点,因此通过映射容器端口的方式并不适用,因为一个客户端要读写文件时,先请求master节点,master节点告诉客户端应该去哪台机器读写,但是端口却是固定的,因此用映射宿主机端口的方式就有问题,因为应用程序不知道你映射了端口,会出现连接的情况。如果是windows环境,这里有一个解决办法,是将docker的ip加入系统路由,这样就可以不需要端口映射,直接在宿主机内开发测试。
1 | # 172.19.0.0/16是我自定义的hadoop子网 |
启动容器
1 | # 启动master容器 |
启动Hadoop集群
1 | # 进入master容器 |
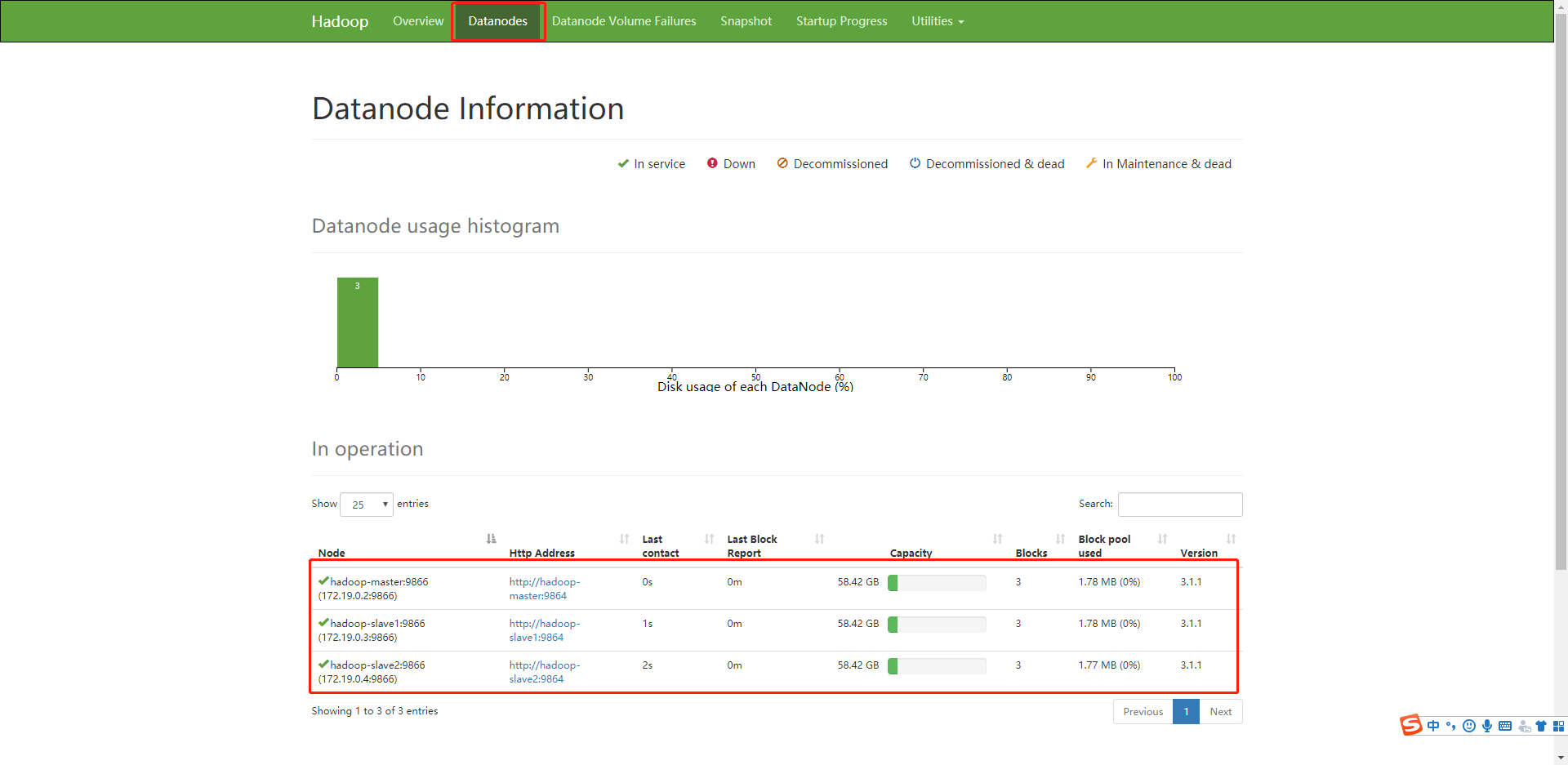
验证集群启动成功
1 | # 浏览器输入,ip要根据自己的,端口hadoop3.0之后管理页面端口换成了9870 |
结果,点击datanode,可以看到有三个数据节点,说明启动成功。
开发第一个HDFS程序
创建一个空的maven项目
加入jar依赖
1 | <dependency> |
编写读写hdfs的代码
1 | package com.hadoop.hadoop_demo.service; |