Spark概述
Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。[1]Spark允许用户将数据加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法。摘自维基百科。总结一下就是,hadoop的mapreduce是将中间结果存在磁盘上,而spark是将中间结果存在主存中,所以速度比Hadoop的mapreduce快。
准备工作
环境选择
- 宿主机系统:win10
- hadoop版本:3.1.1(构建基于HDFS的spark)
- Spark版本:2.4.5
- 容器系统:ubuntu16
- jdk:1.8
准备
- 下载jdk1.8下载地址放入E:/docker/spark目录下
- 下载Hadoop下载地址放入E:/docker/spark目录下,这一步不是必须的,只是因为我部署hdfs的时候选择了版本3.1.1不想重新部署,所以下载Spark时选择了Pre-build with user-provided Apache Haddop,啥意思呢?就是自定义版本的Hadoop,如果选择的Spark版本是Pre-build for Apache Haddop 2.6/2.7,那就不需要单独下载Hadoop,因为下载的Spark已经预编译了。
- 下载spark下载地址放入E:/docker/spark目录下,选择好自己的版本,如果已经安装了Hadoop2.6/2.7建议直接下载预编译了Hadoop的版本,不需要后续配置环境参数。
- 关于Hadoop集群的部署可以参考Hadoop学习笔记(1)-环境搭建
编写Dockerfile文件
1 | FROM ubuntu:16.04 |
配置配置文件
1 | # 将两个文件放入E:/docker/spark/config目录下 |
构建镜像
1 | # cd切换目录到E:/docker/spark目录 |
启动
运行镜像
镜像已经构建完成下面开始启动镜像并启动spark
1 | # 因为要利用hdfs,所以我将它和hadoop放入同一个网段 |
验证
1 | # 浏览器输入,将ip换成自己对应的ip,spark的web ui端口默认是8080 |
执行第一计算任务
创建一个java的maven空项目
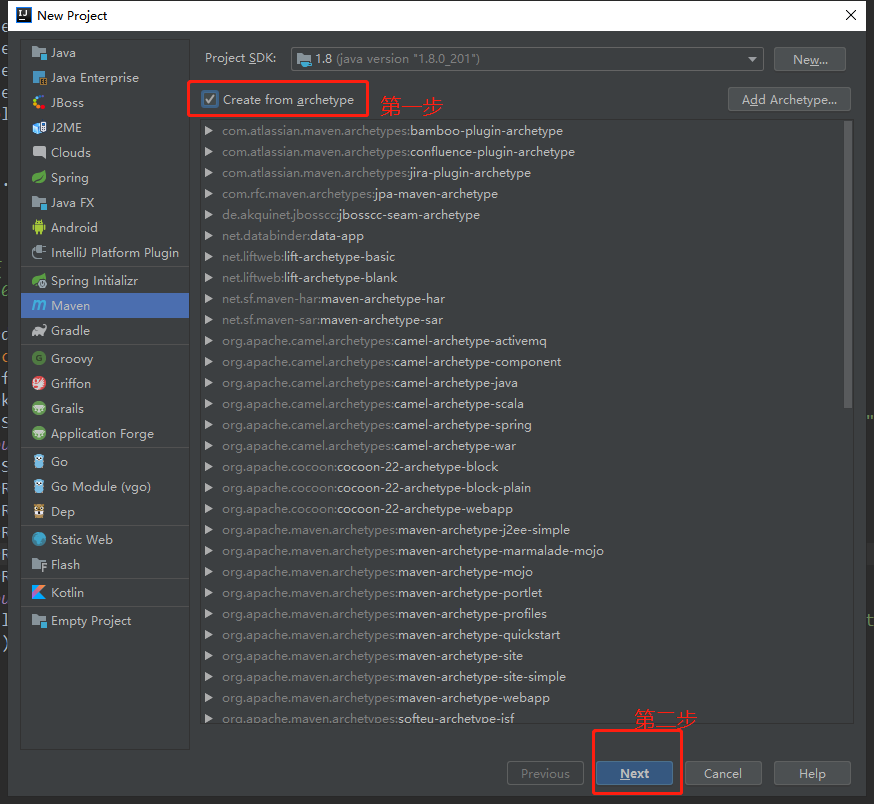
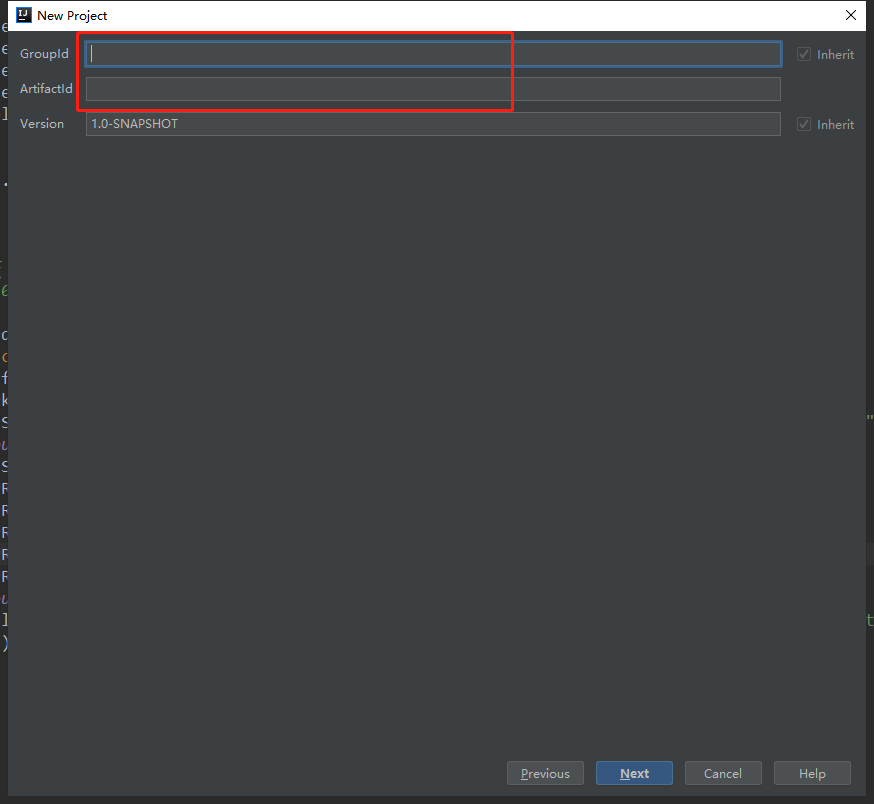
填写groupid等信息
配置spark开发jar依赖
需要下载的jar相关依赖很多,可能要等很久看个人网速
1 | <dependency> |
编写计算任务代码
这里我是写的一个词频统计的
1 | package com.hou.test; |
编译打包
1 | mvn clean package |
复制到spark容器
1 | docker cp study.word.count-1.0-SNAPSHOT.jar spark-master:/tmp |
提交任务到spark执行
如果没有明显报错信息,就说明执行成功。
1 | # spark/bin目录下 |
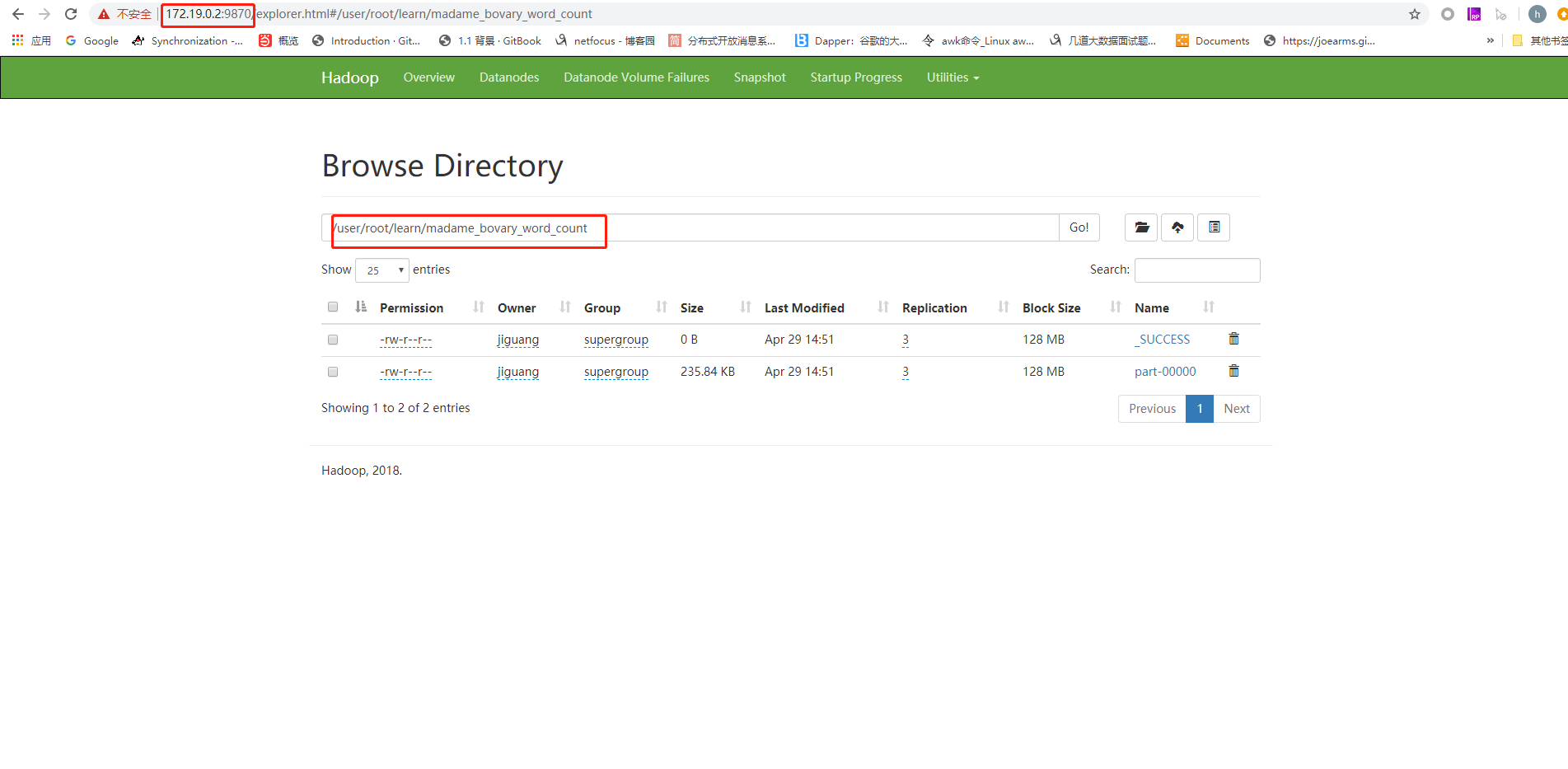
查看运行结果
在hdfs上查看运行结果,如果看到madame_bovary_word_count目录,点进去如果有结果说明词频统计以完成并将结果写入了HDFS。