背景
前段时间利用Docker部署了hadoop集群和spark,也简单的提交了任务。但是肯定有一个疑问,如果我们要执行定时任务怎么办呢?或者我们执行复杂的具有顺序的多任务怎么办?在大数据中,这种场景非常常见,一个大数据任务通常由大量的任务组成,并且可能是shell脚本、mapreduce任务、spark任务等,并且任务之间存在依赖关系。手动执行这种原始办法虽然可以,但是人总有出错的时候。今天要带来的一款具有复杂任务调度能力的框架-Azkaban,也支持定时调度。
Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器
Azkaban特点
- 兼容任何版本的hadoop
- 易于使用的Web用户界面
- 简单的工作流的上传
- 方便设置任务之间的关系
- 调度工作流
模块化和可插拔的插件机制
认证/授权(权限的工作)
- 能够杀死并重新启动工作流
- 有关失败和成功的电子邮件提醒
上面的描述太抽象?一个技术要想了解,必须得自己捣鼓一下,接下来我将用Docker来部署,Docker用来学习安装软件不要太舒服,一来它可以很方便的给你提供Linux环境,二来不用将软件装在自己电脑上,久而久之电脑变得很卡特别是win环境。
Docker部署Azkaban
环境准备
- 宿主机系统:win10
- hadoop版本:3.1.1(构建基于HDFS的spark)
- Spark版本:2.4.5
- 容器系统:ubuntu16
- jdk:oraclejdk1.8.0.251
- azkaban:开发版
配置Dockerfile
1 | # 配置ssh免密登陆 |
azkaban配置文件
关于spark的配置文件可以参考Docker部署Spark并提交WordCount任务,我把上一篇的openjdk换成oraclejdk,openjdk在编译azkaban时有ssl问题。
配置build.gradle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24buildscript {
repositories {
maven {
url 'https://maven.aliyun.com/nexus/content/groups/public/'
}
mavenCentral()
}
dependencies {
classpath 'com.cinnober.gradle:semver-git:2.2.3'
classpath 'net.ltgt.gradle:gradle-errorprone-plugin:0.0.14'
}
}
allprojects {
apply plugin: 'jacoco'
repositories {
maven {
url 'https://maven.aliyun.com/nexus/content/groups/public/'
}
mavenLocal()
mavenCentral()
}
}拷贝一份build.gradle文件修改maven仓库地址,这里是为了gradle构建azkaban项目时,配置国内maven镜像仓库,速度可以快一些。
配置commonprivate.properties
1
2execute.as.user=false
memCheck.enabled=false配置Azkaban执行任务时不检查内存,azkaban默认执行job会检查内存是否大于3G,docker部署的容器默认没有分配这么多内存,所以如果没有配置不检查内存,执行任务可能会失败。
构建镜像
老规矩,cd切换到对应的目录,执行时间可能比较长,因为编译azkaban需要下载jar。我在Dockerfile配置中跳过了azkaban测试,不然时间更长。
1 | docker build -t hou/az-so-spark . |
启动容器
这里启动容器设置了网络和Hadoop集群一个网段,方便调用hdfs
1 | docker run -dit --name az-so-spark --hostname az-so-spark --net hadoop hou/az-so-spark |
启动Azkaban和Spark
1 | docker exec -it az-so-spark /bin/bash |
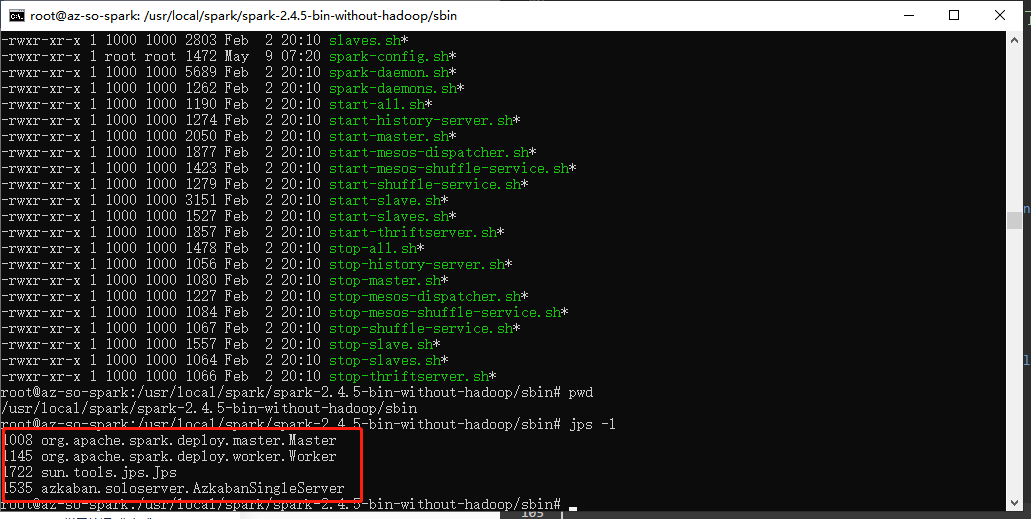
检查azkaban和spark进程
1 | jps -l |
可以看到如图
任务调度
spark程序
用上一次部署spark时用的wordcount程序
编写Azkaban脚本
1 | # wordCount.job |
可以看到azkaban的command type调度本质上是执行shell命令
压缩打包zip
将study.word.count-1.0-SNAPSHOT.jar和wordCount.job文件打包为zip格式
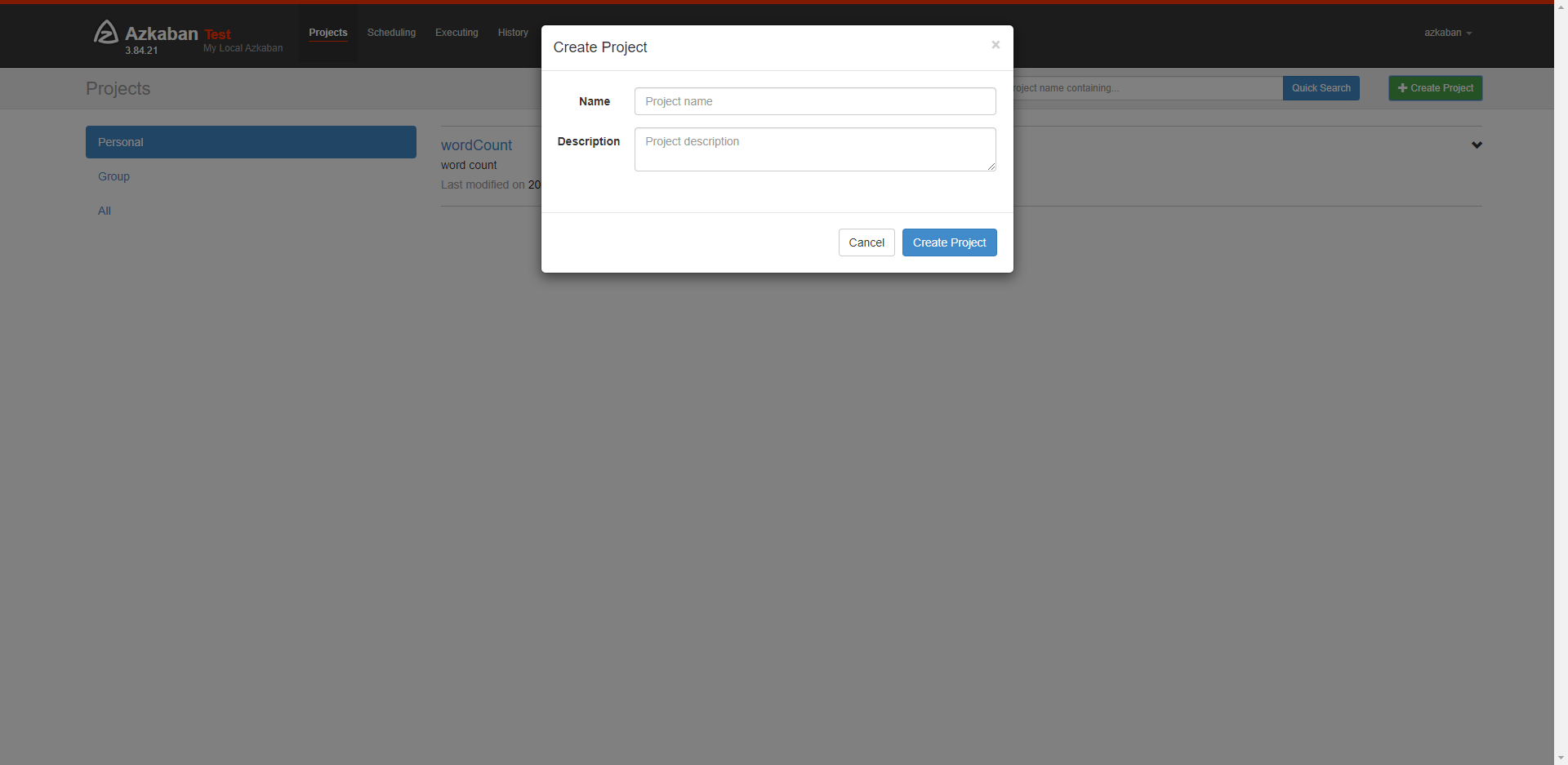
创建项目
登录azkaban管理后台,默认端口8081,name和password默认都是azkaban,首页点击create project
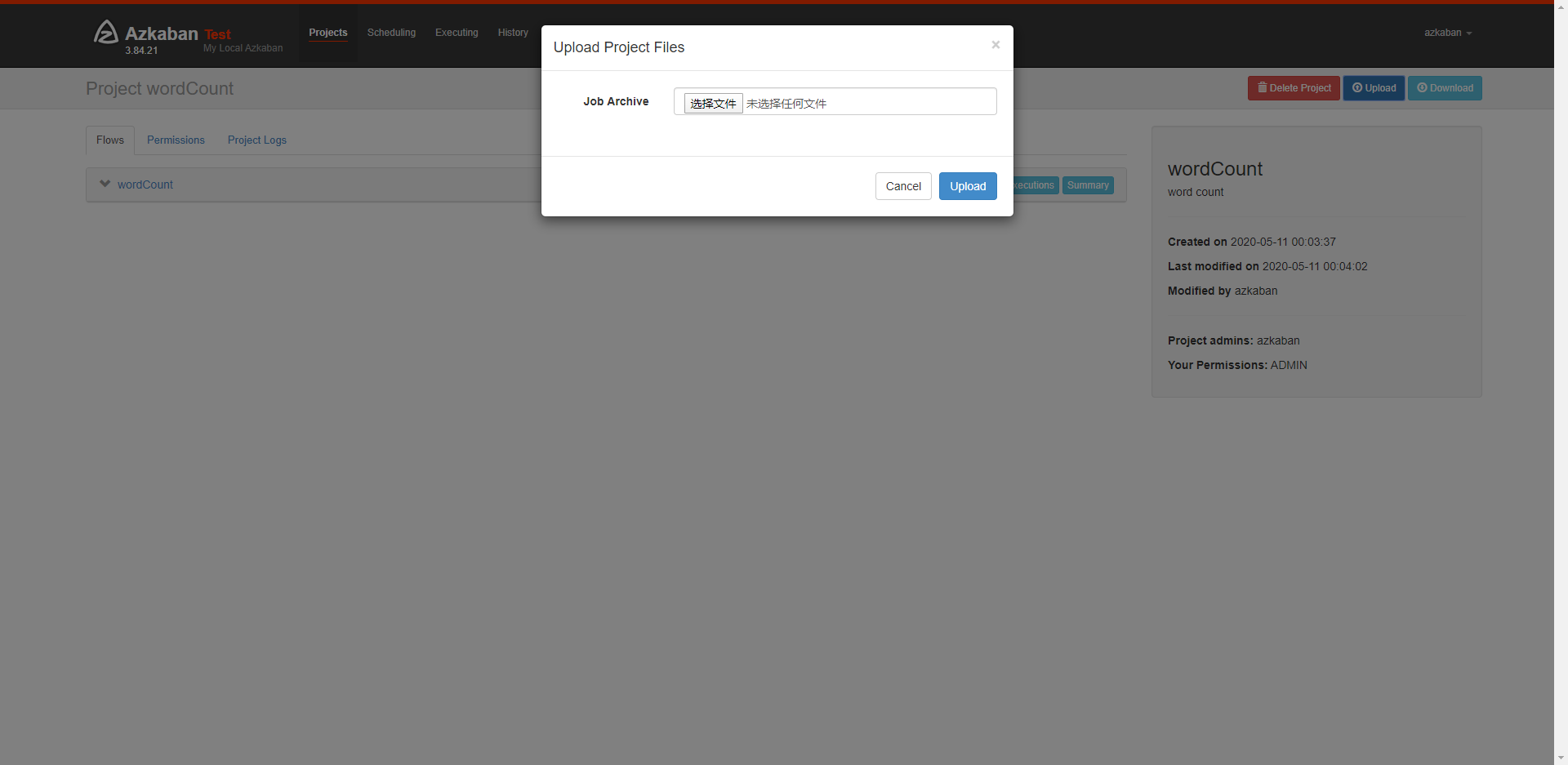
上传压缩包
azkaban这里压缩包格式要用zip,点击刚才创建好的项目,然后点击upload
执行和查看结果
执行
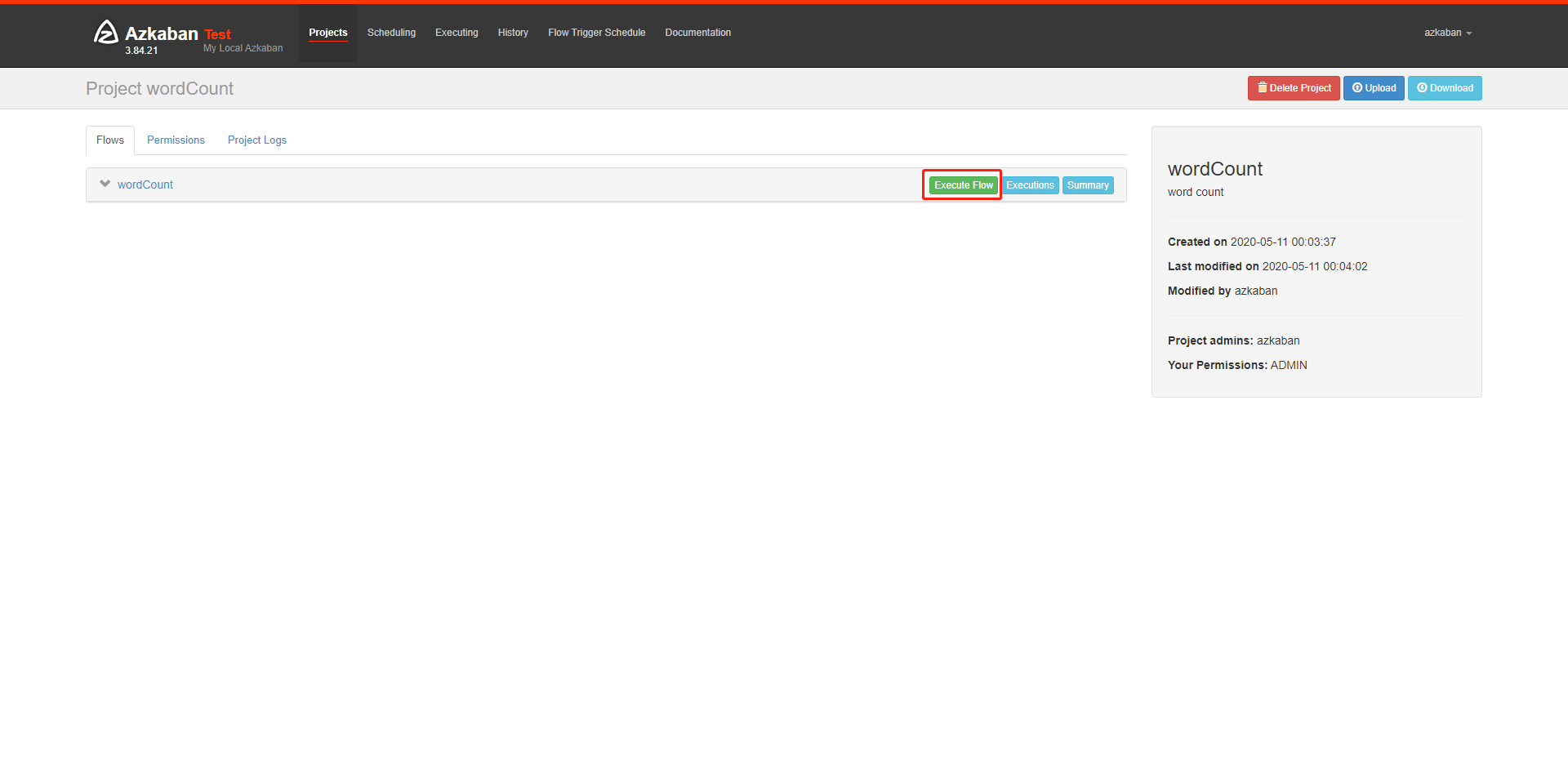
我选择了实时执行,这里也可以选择schedule,设置定时任务执行
查看结果
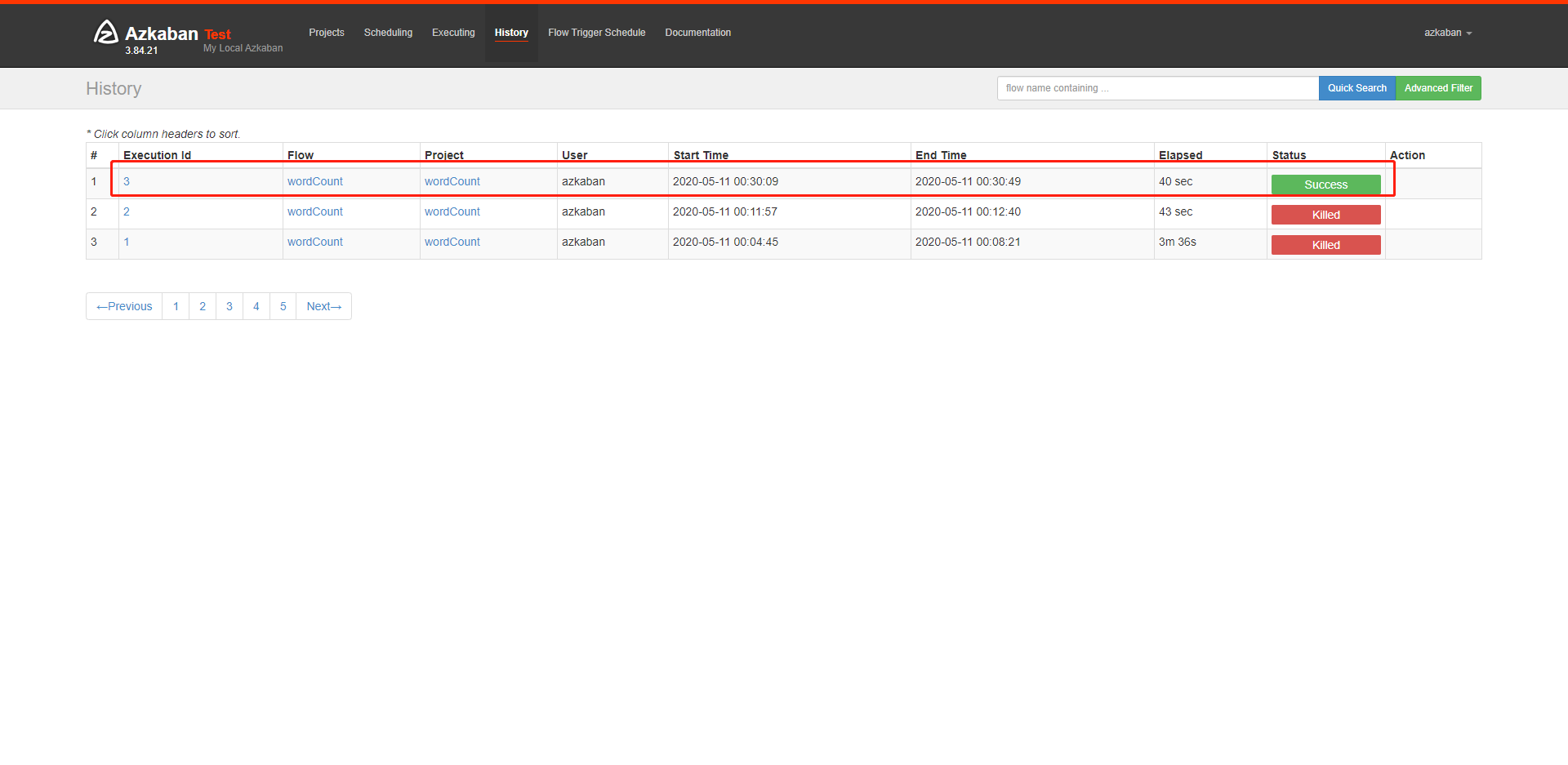
我的这里因为一开始没有配置不检查内存,所以有两次失败的记录