引言
当我们在平时工作或学习中用电脑的时候,我想很多人都是一边听着音乐一边写代码、看文档、编辑Markdown写笔记或者Chrome看着网页,不知道你有没有好奇电脑为什么可以可以同时完成这些程序的运行,并且如果你细心可能发现了有时候程序的响应快,有时候响应慢。这些都是因为进程&线程调度的结果,哪怕你的电脑处理器只有一核,可同时同时执行多个应用程序。
为何需要调度
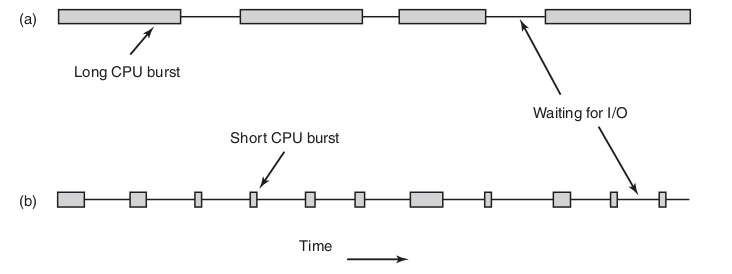
并不是所有的程序都是cpu密集型的,也有I/O密集型,如下图,a是cpu密集型任务,它有很长的cpu周期,而b则持有cpu的时间短但是却很频繁。如果你是系统的设计者你会让程序如果运行呢?如果每次都先执行完a再执行b,那么磁盘可能长期处于空闲状态,这里有一个简单的想法是,优先保证b进程执行,这样磁盘就可以长期保持忙碌的状态。所以,进程调度的目的一方面是让程序并发执行,一方面是为保持系统各个组件处于忙碌状态避免资源浪费。
下面的笔记是探索进程&线程调度的笔记,一步步揭开处理器调度神秘的面纱。本文的结果,先介绍一些调度的基本概念方便理解后边的内容,然后会介绍调度算法(以单核和进程为视角介绍,线程和进程差不多的),之后会介绍线程调度的特有特征,然后介绍多核心环境下调度,最后可能会简单的举个例子介绍实际OS采用的是什么调度策略。
基本概念
调度器
调度器是操作系统实现的,通过一定的算法从一堆就绪线程中选择一个,然后完成上下文切换,然后执行新调度线程的代码的一个线程,注意调度器也是一个线程,它是一个高优先级的内核线程。
抢占式与非抢占式
- 非抢占式:挑选一个进程一直运行,直到进程阻塞(I/O或等待其他线程)或者自愿让出cpu
- 抢占式:挑选一个进程执行固定的时间,当进程用完最大时间还在执行时会被挂起,然后切换另一个就绪的进程,并且当一个比当前运行进程更高优先级进程到达时,可以抢占当前进程的cpu
何时调度
- 在创建新进程后,需要决策时运行父进程还是子进程
- 在一个进程退出时
- 当一个进程被阻塞在I/O、信号量或者其他原因阻塞时,必须选择另一个进程运行
- 在一个I/O中断时
调度环境
- 批处理:适合非抢占式算法,减少进程切换
- 交互式:抢占是必须的,不能让一个进程一直霸占CPU
- 实时:对deadline要求严格
调度算法的目标
- 公平:相似的进程应得到相应的服务
- 策略强制执行
- 平衡:保持系统各个部分尽可能忙碌
- 批处理三个指标
- 吞吐量:最大化每小时运行工作数
- 周转时间:任务提交到运行结束的平均统计时间,时间越小越好
- CPU利用率:保持cpu在所有时间内忙绿
- 交互式系统指标
- 响应时间:快速响应用户请求
- 均衡:满足用户期望
- 实时系统
- 满足截止时间:避免错过数据
- 可预测性:避免在多媒体系统中品质降低
批处理系统调度算法
Frist-Come Frist-Served(FCFS)
- 原理:顾名思义,就是先到的进程先调度,假设进程到达的顺序是p1->p2->p3

p2等待时间是24ms,p3等待时间是27ms,所以平均等待时间17ms,现在假设进程到达的顺序是p2->p3->p1那么如下图,平均等待时间是3ms

- 缺点
- 平均等待时间长
- 不能很好平衡CPU和I/O的利用率, 如果遇到计算密集型任务(会长期霸占cpu),可能导致I/O空闲
最短作业优先(SJF)
原理:每次调度都选择下一次执行时间最短的作业执行,假设4个进程的需要的cpu突发时间如下图

都是就绪状态那么调度顺序将如下图

平均等待时间为7ms,如果用FCFS算法,平均等待时间可能为10.25ms
缺点
只有在进程可以同时就绪时,SJF才是最优的
无法获得下一次进程的cpu突发时间,可以利用一种指数平均方法来估计下一次cpu突发时间
$\tau_{n+1}$代表第n+1次的预测值,$t_n$代表第n次实际时间,$\alpha$代表历史实际突发时间权重,$0 \le \alpha \le 1$,通常取$\frac{1}{2}$
最短剩余时间优先
原理:基本思想和SJF相同,但是多了一点,最短剩余时间优先是可以抢占的,假设进程的到达时间和cpu突发时间如下图

实际调度顺序

p1最先到达,但是p2在p1执行1时到达,因为p2的cpu突发时间比p1剩余的cpu突发时间更短,因此p2抢占p1的进程。平均等待时间是$[(10 − 1) + (1 − 1) + (17 − 2) + (5 − 3)]/4 = 26/4 = 6.5$。
交互式系统调度算法
轮转调度(Round-Robin Scheduling RR)
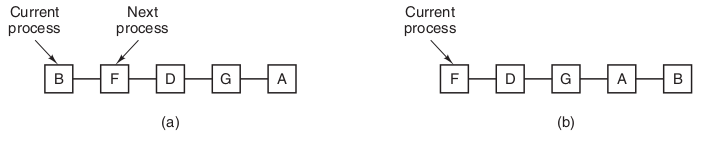
原理:类似FCFS算法,添加了抢占和时间片概念。为每一个进程分配一个时间片运行,在时间片结束前阻塞或结束,则CPU立即进行切换,或者进程用完分配的时间片,进程被挂起,切换就绪队列的头运行。时间片长度一般从10-100ms。就绪队列可以看成是一个循环队列,每个用完时间片的进程又加入到队列尾部,结果如下图
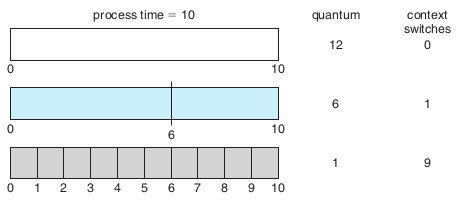
一个简单的例子,假设进程cpu突发时间为10,下图是时间片为1,6,12时,上下文切换的次数,可以看出时间片越短,上下文切换次数越多
缺点
时间片太长,RR算法可能会退化成FCFS
时间片太短,如上图,上下文切换的次数将增加,进程周转时间越大。
$浪费时间 = 上下文切换时间 / 时间片$
优先级调度(Priority Scheduling)
原理:每个进程都被分配了一个优先级,cpu将会被分配给高优先级的进程,同等优先级的进程采用FCFS算法调度
- 可抢占优先级调度:当一个新的进程到达且优先级比当前cpu执行的进程高时,新进程可以抢占当前进程的cpu
- 非可抢占优先级调度:当一个新的进程到达且优先级比当前cpu执行的进程高时,只是简单的将新进程加入队列的头部
一个简单例子,假设一个p1,p2…p5集合在时间0到达,cpu突发时间和优先级如下
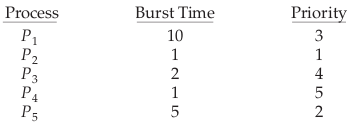
它们的调度顺序如下图

缺点:饥饿,低优先级的进程可能无限期的等待,或者高优先级的进程一直霸占CPU,有几种解决方法
对于低优先级进程可以引入老化,定期提升一直未获得cpu的低优先级进程的优先级。比如假设优先级范围为0-127,定时时间为1s,一个最低优先级127的进程,只需要2min左右的时间就可以提升0
结合轮转调度,同一优先级的进程会采用轮转调度,比如

它们的调度顺序会是这样

多级队列调度
原理:按不同进程的特征,划分为不同的类别,然后不同类别的进程有不同的优先级,有独立的调度队列,采用不同的调度算法,比如
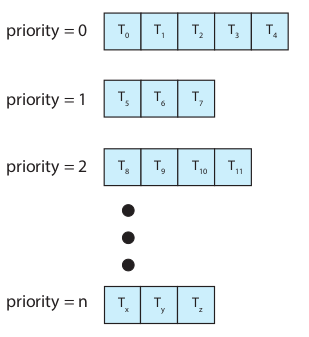
举个例子,首先实时任务的优先级最高,因为实时任务有deadline要求,其次是系统任务,然后是交互式任务,最低优先级为批处理。每个优先级有自己的调度算法,比如交互式任务可以用RR调度,而批处理任务可以用FCFS调度
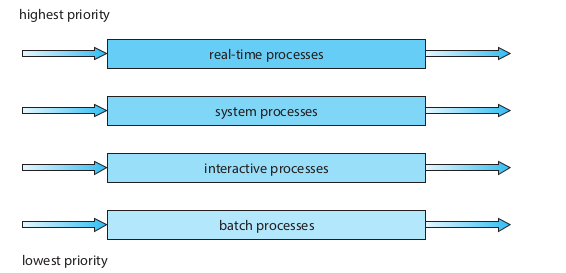
多级反馈队列调度
原理:多级反馈队列调度同样是对于不同优先级的进程有多个队列,进程在队列之间是可以移动的,它的核心思想是CPU密集的进程会逐渐移动到低优先级队列,而I/O密集和交互式进程可以在高优先级队列保持低延迟响应。为了防止饥饿,长时间等待的低优先级进程可以升级到高优先级队列。每级队列可以采用独立的调度算法。
简单举个例子,如下图,有三级队列,每个新来的进程会进入0级队列,假设此时有1级队列的进程正在执行,则会被新进程抢占cpu。0、1级队列都采用RR调度算法,2级采用FCFS调度算法,当0级的进程时间片用完后将降级加入1级队列
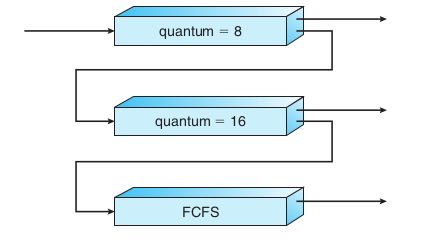
多级反馈队列调度关键参数
- 队列数
- 每级队列的调度算法
- 决策提升优先级的方法
- 决策降低优先级的方法
- 决策进程进入哪级队列的方法
实时系统调度算法
实时系统和批处理和交互式系统不同,这里先列出一些实时系统的基本概念
基本概念
实时系统分类
- 软实时系统:虽然也有时限要求,但是并不保证在deadline执行,错过时限也不会导致严重的后果
- 硬实时系统:硬实时系统,严格的时限要求,任务必须在deadline执行,错过了deadline意味着严重的后果
最小延迟
事件延迟,从事件的发生到事件响应的事件
中断延迟:cpu收到中断时,要做两件事,第一检查中断类型,第二上下文切换保存当前正在执行线程的状态,这段时间就是中断延迟。有一个重要因素是当内核数据结构更新时是禁止响应中断的,因此实时系统要求禁止响应中断的时间非常短
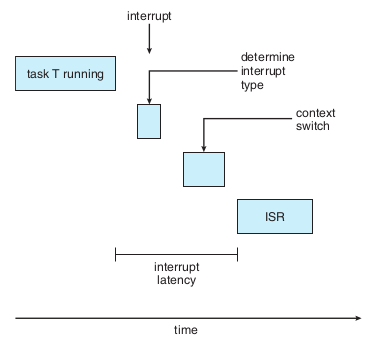
分派延迟
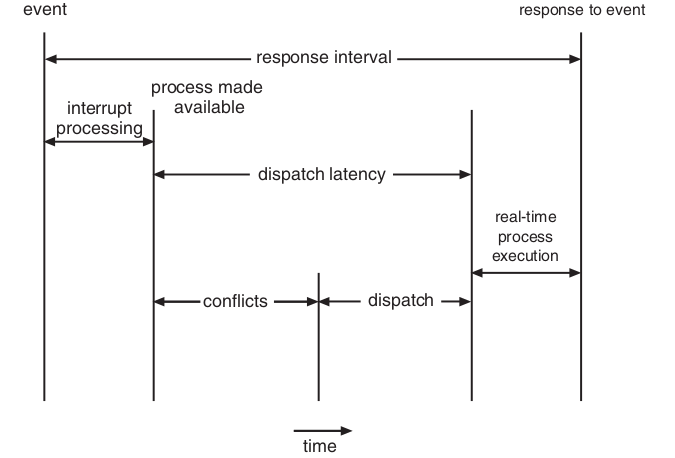
conflicts阶段
抢占正在运行的进程
低优先级进程释放高优先级进程需要的资源
dispatch阶段:调度高优先级进程到可用的cpu
基于优先级的调度
- 原理:给实时任务分批较高的优先级
- 缺点:基于优先级的抢占式调度算法只能保证软实时
Rate-Monotonic Scheduling(RMS)
基本假设
- 假设调度周期性任务
- 假设每个任务进入系统会被分配一个固定优先级,周期越短优先级越高,周期越长优先级越低
- 假设任务的deadline是下一次执行前
实际例子分析
假设第一个进程P1周期为50,cpu时间为20,第二个进程P2周期为100,cpu时间为35
计算cpu利用率
$U_{cpu} = 20/50 + 35/100 = 0.75$
假设p2先运行,那么p1就无法在deadline50完成
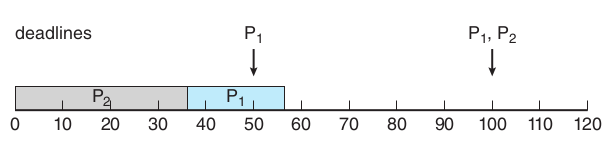
假设p1先运行

假设第一个进程P1周期为50,cpu时间为25,第二个进程P2周期80,cpu时间为35
计算cpu利用率,cpu利用率96%感觉可以运行,接下来分析一下调度
$U_{cpu} = 25/50 + 35/80 = 0.96$
无论如何调度,都无法满足

结论:不能利用cpu最大利用率来确定是否能成功调度,应该取调度N个进程时最差的cpu利用率,当需要调度的任务cpu利用率超过该值时,无法调度,由此可见,RMS调度算法cpu利用率较低。N个进程最差的cpu利用率计算公式: $U_{worstN} = N(2^{\frac{1}{N}}-1)$
Earliest-Deadline-First Scheduling(EDF)
原理:根据任务的deadline动态调整进程的优先级。理论上是最优的算法,既能保证进程满足deadline又能保证cpu有很好的利用率
举个简单的例子,假设第一个进程P1周期为50,cpu时间为25,第二个进程P2周期80,cpu时间为35

和RMS比较
- 不需要任务是周期性任务
- 不需要任务cpu执行时间是常数
Proportional Share Scheduling(PSS)
- 原理:按比例分享cpu时间,admission-control会接收一个请求如果有足够的比例份额,否则会拒绝请求,假设A需要50、B需要20、C需要15,当新来的D需要30,则会被拒绝
线程调度
上面所有算法都是以进程为调度目标是为了简化,线程调度算法和进程的是一样的,其实现代操作系统调度的都是内核线程。下面是上边没有介绍到的线程调度的区别
竞争范围
- PCS:进程竞争范围,在many-to-one和many-to-many线程模型中,用户级线程调度器调度用户线程运行在一个可用的LWP上,当用户线程获得可用LWP并不意味着该线程正运行在cpu上,还要取决于LWP的内核线程是否被调度获得物理CPU
- SCS:系统竞争范围,所有内核线程竞争cpu
多处理器调度
多处理器的种类
- 多核心
- 多线程内核(Intel的超线程)
- NUMA系统
- 异构多核处理器(ARM,多为移动设备芯片)
非对称多处理器
- 所有的调度、i/o和其他系统活动处理都在同一个处理器上(master),其他处理器负责执行用户代码。
- 优点,只有master处理器访问系统数据,减少数据共享
- 致命缺点:master处理器成为瓶颈
对称多处理器(SMP)
所有处理器自调度
调度队列
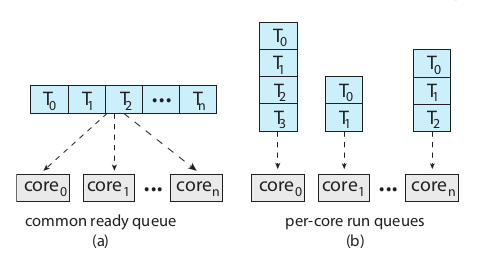
- a共用一个队列,导致的问题是queue的竞态问题,需要同步操作,否则可能两个core取了同一个thread,那么queue的锁成了性能的瓶颈
- b最通用的方法,解决了通用queue锁的瓶颈问题,而且可以有效利用缓存。有一个问题是工作量均衡问题,可用通过一个平衡算法来均衡各个处理器的工作量
多核心处理器memory stall问题
当处理器执行代码需要访问主存时,因为访问主存很慢,导致会浪费很多cpu周期
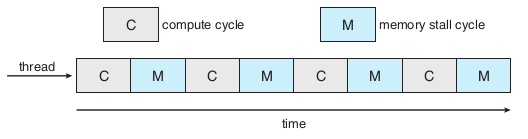
解决办法:芯片多线程技术(CMT),例如Intel的超线程,也就是我们平时总看到的i5双核四线程,就是每个核心有两个hardware thread
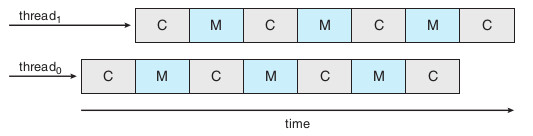
CMT处理器的结构,hardware thread共享物理芯片资源,比如缓存和流水线
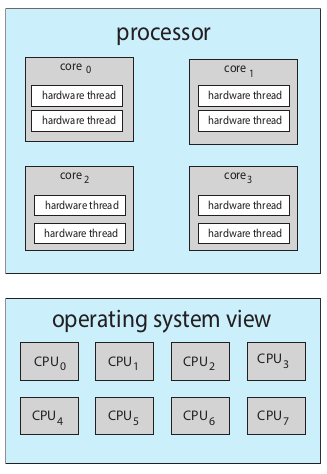
CMT实现
- 粗粒度:发生高延迟时切换hardware thread,上下文切换需要刷新指令流水线,因此开销高
- 细粒度:在更细的级别上,比如在指令周期的边界
实际两级调度
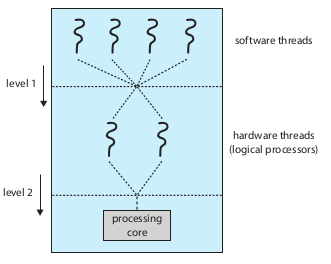
- 简单轮转调度算法:Ultra SPARC
- urgency优先级,每次切换时比较哪个优先级更高:Intel Itanium
负载均衡
- Push migration:一个特殊任务定期检查,如果检查到不平衡,就会将线程从高负载的cpu移到空闲或低负载的cpu
- Pull migration:当cpu空闲时会主动从高负载的cpu拉去任务
- 负载均衡会导致一个问题,当一个已经执行过的线程因为负载均衡被迁移到其他cpu时,其缓存将失效,需要的数据需要重新从主存加载
处理器亲和
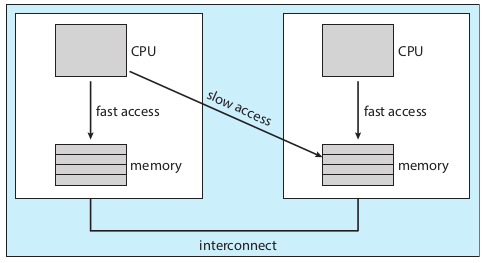
定义:处理器亲和指的是一个线程在一个处理器上运行,当处理器再次调度它时,有缓存的优势,如果它再次执行的时候被迁移到其他cpu执行,那么之前cpu的缓存将失效,并且当前cpu需要重新从主存中加载缓存,因此处理器亲和的优势可能会被负载均衡抵消
软亲和:系统试图保证现在在同一个cpu上调度,但是不能保证
硬亲和:系统提供了系统调用使进程可以指定一个cpu子集供进程的线程运行
处理器亲和在NUMA系统中非常重要,因为每个cpu芯片有自己本地主存,访问远程主存是很慢的
案例:Linux调度
分类调度
默认的完全公平调度(CFS)(内核2.6.23)
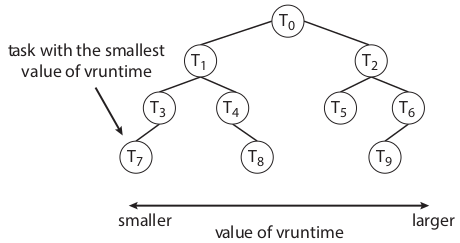
两个概念
- nice value:范围-20~+19,用来映射优先级,值越小优先级越高
- virtual run time:虚拟运行时间,当nice value为0,该时间为物理运行时间;当nice value越大,说明优先级越低,cpu时间比例越小,那么该时间大于真实运行时间;反之优先级越高,cpu时间比例越高,该时间小于真实运行时间
不采用固定时间片,而是采用比例,这个比例取决于nice value,值越小优先级越高,权重越高,调度周期内获得cpu时间比例越高,也就是连续执行的时间替代时间片
调度: 选择虚拟运行时间最小的调度,因此nice value越小,优先级越高,得到调度的机会越多,就绪队列实现是利用red-black Tree,当一个任务变成不可运行(例如阻塞)会从树中删除
实时调度
- Linux分了两个独立的优先级范围分别给实时任务(0-99)和普通任务(100-139,映射nice value-20~100,19~139)
负载均衡
- 在NUMA架构中,采用分层调度域(一个cpu核心集合),负载均衡不会迁移线程到其他域,防止线程远程访问主存