引言
上一篇学习了虚拟内存,虚拟内存解决了多道程序并发运行的内存分配和解决小内存运行大程序的问题。这一篇将讲解高速缓存,来解决内存的低速和cpu高速不匹配的问题,计算机的很多的问题,其实都可以中间加一层解决,因此计算机才变得复杂,想象一下如果主存的速度可以匹配cpu的速度那么高速缓存就不需要了,再进一步,假设硬盘的速度可以匹配cpu,我想主存也可以不需要了。但是现有的技术还达不到这个目标,所以这一部分还是得学习一下高速缓存,看看高速缓存是如何解决cpu快速访问指令和数据的问题。
基本概念
CPU、缓存、内存架构
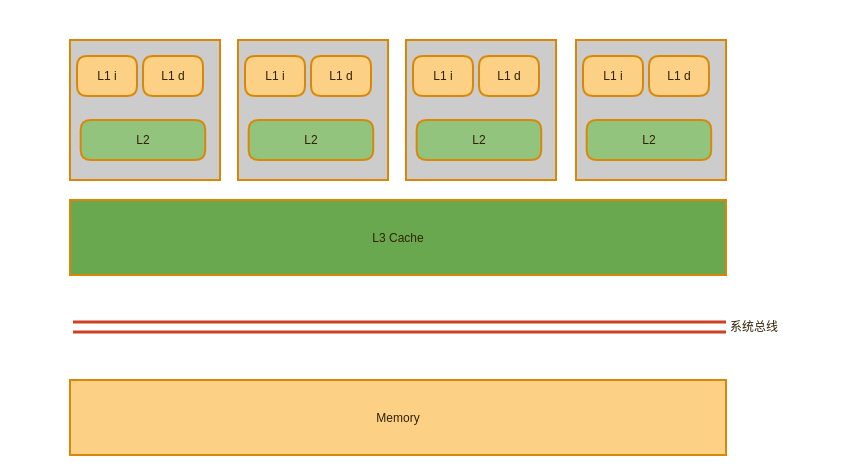
现代cpu一般都是多核的,高速缓存通常分了三级,L1分为指令缓存和数据缓存并且是cpu核心独有;L2也是cpu核心独有;L3则是多核心共享,其示意图如下
通用缓存基础参数
- S:通常代表几路,也代表分组
- E:代表每一路中有多少个缓存行,代表缓存的路数
- B:代表一个缓存行有多少个byte
- 所以缓存的容量为
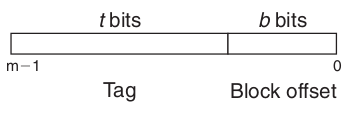
全相联映射
全相联映射地址结构
全相联和内存映射关系,全相联缓存的一个缓存行可能缓存内存中任何一行,检查缓存行时遍历缓存比较tag,然后通过Block offset取值
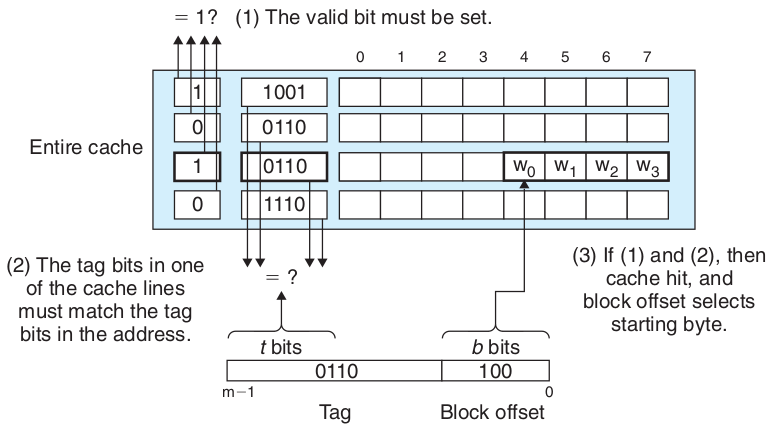
全相联的缺点:全相联判断缓存是否命中时需要比较缓存行中的每一行,电路延迟较长
直接相联映射
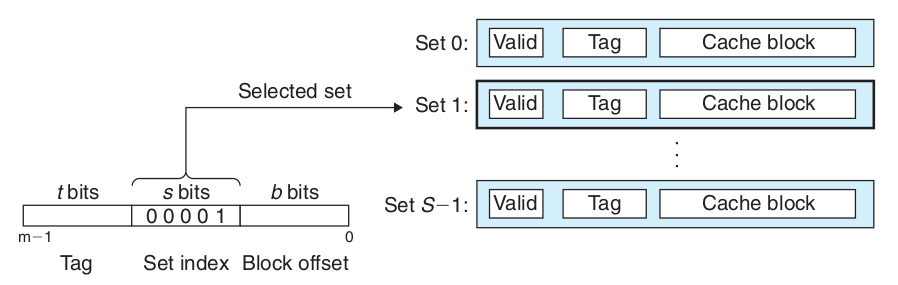
直接相联映射结构,和全相联不同,直接相联的地址分为三部分,tag、set index和Block offset,set index表示将地址映射到缓存的Set上索引,因此内存不在是任意的映射到缓存,而是通过set index位严格映射到对应的缓存Set上,直接相联的映射流程为先求出set index找到缓存中对应的Set,然后判断tag是否一致
直接相联缺点:缓存冲突时,必须被换出,频繁更换内容会造成大量延迟
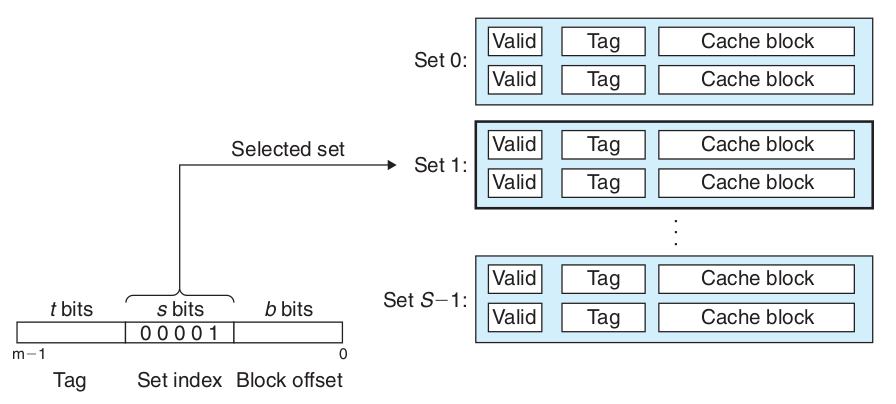
分组相联映射
分组相联映射结构,结合了全相联和直接相联映射的特点,为了解决直接相联缓存冲突导致频繁更换造成缓存的延迟,增加了一个Set中缓存行的行数,可以有效降低缓存的冲突。分组相联映射查找缓存的流程是先求出set index找到对应的缓存分组,然后遍历分组中缓存行的tag,对比是否命中。分组相联的结构如图
一个实际cpu的缓存行

缓存写策略
- Cache命中时写策略
- 写穿透,数据直接写回缓存和主存
- 回写,数据写回缓存,仅当数据块被替换时,将数据写回主存
- Cache未命中时写策略
- 写不分配,直接将数据写回主存
- 写分配,将数据块读入缓存,然后在写回缓存
缓存替换策略
- 随机替换
- 轮转替换
- 最近最少使用LRU
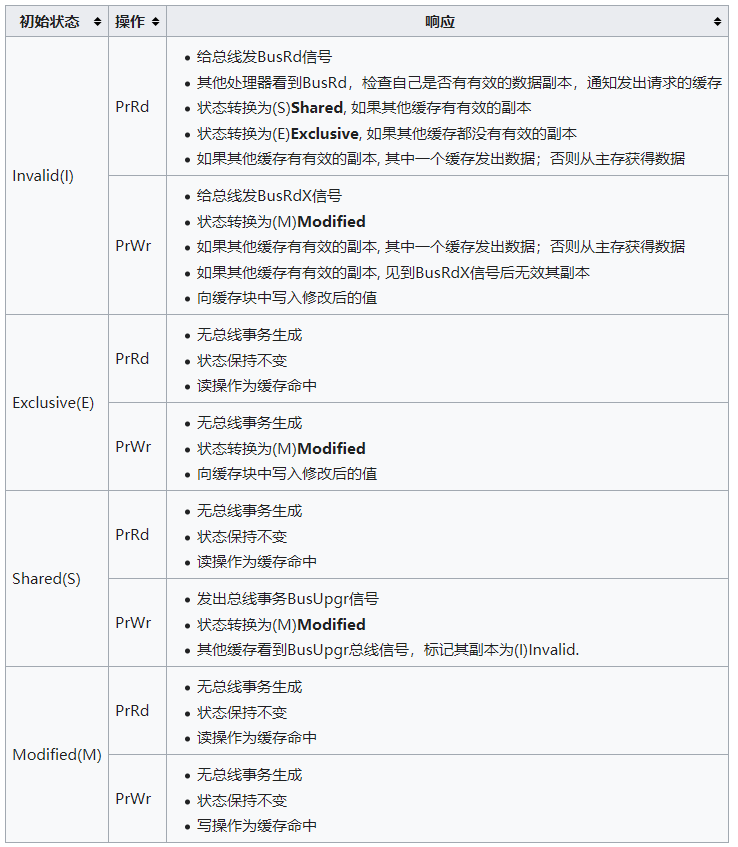
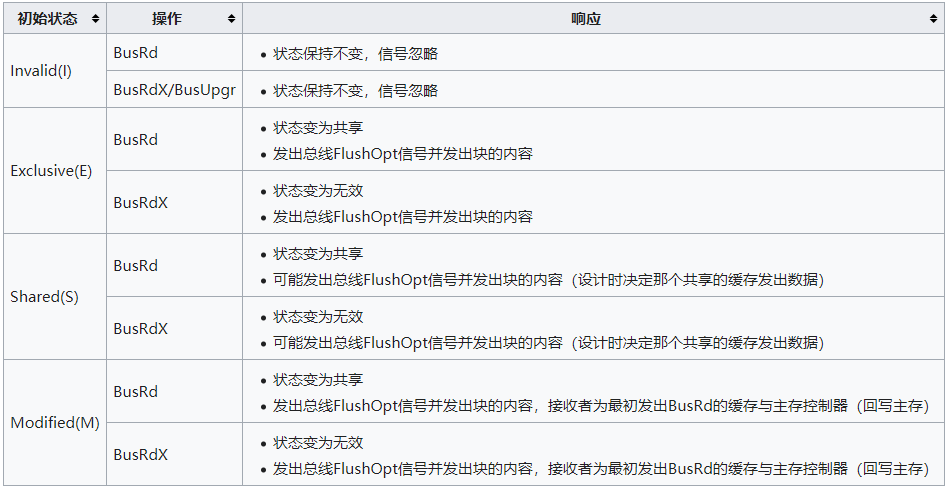
MESI缓存一致性协议(四个状态的首字母)
定义:MESI协议是一种窥探协议,cache和cache之间的数据传输发生在同一条总线上,cache不但与主存通信和总线打交道,还会窥探总线上发生的数据交换,跟踪其他cache在做什么
四种状态
- Modified:缓存行是脏的(dirty),与主存的值不同
- Exclusive:缓存行只在当前缓存中,但是干净的(clean)—缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为Modified状态
- Shared:缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃
- Invalid:缓存行是无效的
操作
- cpu对缓存的请求
- PrRd: 处理器请求读一个缓存块
- PrWr: 处理器请求写一个缓存块
- 总线对缓存的请求
- BusRd: 窥探器请求指出其他处理器请求读一个缓存块
- BusRdX: 窥探器请求指出其他处理器请求写一个该处理器不拥有的缓存块
- BusUpgr: 窥探器请求指出其他处理器请求写一个该处理器拥有的缓存块
- Flush: 窥探器请求指出请求回写整个缓存到主存
- FlushOpt: 窥探器请求指出整个缓存块被发到总线以发送给另外一个处理器(缓存到缓存的复制)
- cpu对缓存的请求
状态转换图
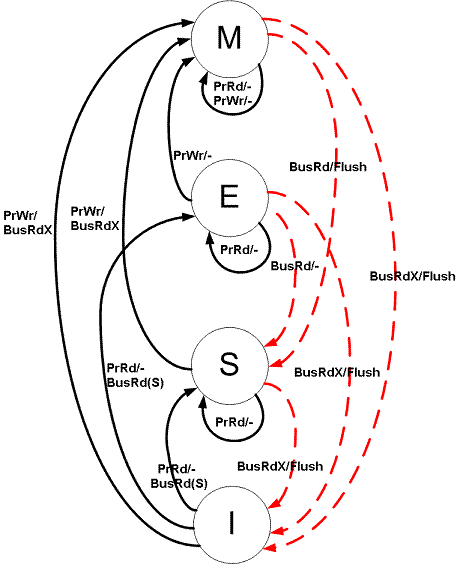
cpu请求缓存的响应
总线请求缓存的响应
缓存实际运用
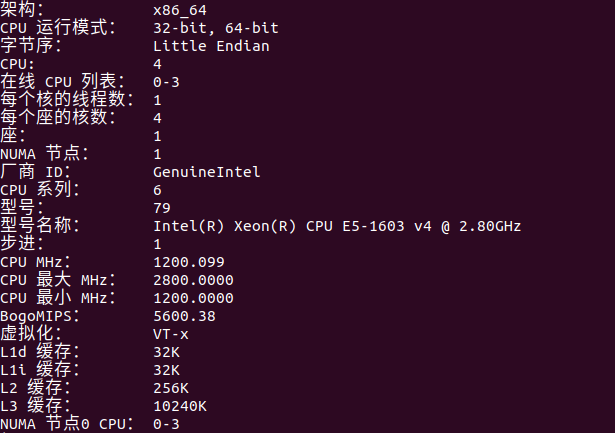
查看cpu缓存信息
1 | lscpu |
如下图,L1d和L1i分别为32kb,L2为256kb,L3为10240kb。
查看L1缓存的路数和行数,64组8路块大小64bytes的缓存

缓存测试
1 | public class CacheTest { |
为了测试一下有效利用缓存的区别,写了上边的测试代码,因为缓存行的块大小为64bytes,所以我们定义一个二维数组,每行16个int值,刚好是64bytes,也就是一个缓存行。
测试结果,sum1是按列的顺序求和,执行时间在1000ms左右;sum2是按行求和,执行时间为140ms左右,由此可见缓存命中与否对性能有很大的差别