引言
过去几十年CPU速度的增长是巨大的,但是磁盘的访问速度却增长较慢。内存近些年发展也很快,可以提供较大的空间存储程序的工作集,因此磁盘传输主要是被写操作支配。因此如何提升写效率是有效利用磁盘的关键。
日志结构文件系统是用顺序写,因为省去了绝大部分seek操作,因此大大提升了写的性能。还有一个好处就是系统崩溃恢复,日志结构文件系统只需要检查最近的部分日志
日志结构文件系统实现
基本假设
- 大部分的读请求都从缓存中读取
- 大部分磁盘访问都是写请求
段概念
段定义:虽然磁盘顺序写效率高,考虑一下,如果有一个文件执行写操作就写,但是如果中间间隔一会儿写另一个文件,那么中间磁盘已经旋转。要想获得高效率,必须连续顺序写,因此需要在内存中缓存修改的块,直到达到一定数量的时候执行一次写操作,这个大块叫做段
段布局:段中不仅包含了数据块,也包括i-node块,段的开头还包括一个段summary块,包含了垃圾回收需要的关键信息,后边详细解释
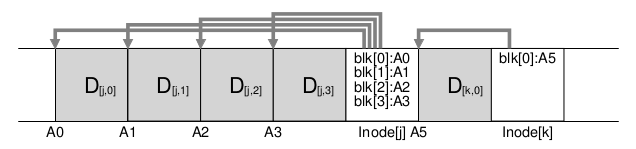
缓存大小:代表写操作前旋转和寻道开销时间,磁盘传输速率MB/s,因此传输MB需要的时间
写效率
写效率是以传输速率为基准,用F(0<F<1)表示
变换得到
假设要得到90%的效率,假设为0.01秒,磁盘传输速率为100MB/s,因此计算D为9MB,因此缓存大小为9MB
I-node查找
i-node查找问题:因为i-node信息现在存放在各个段中,这就引入了一个新文件,如何查找i-node,如果遍历查找肯定不行效率太低。引入了一个新的结构imap,imap是一个简单的数组结构index为k的元素存放着第k个i-node在磁盘的地址,imap信息常驻在内存中,因此查询i-node的位置是很快的
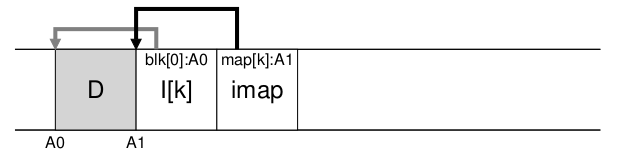
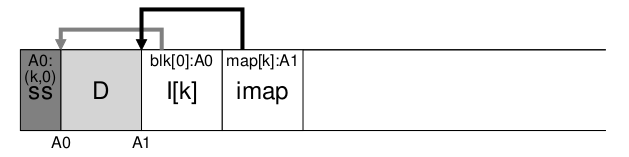
imap存储问题:imap也是需要存储的,这里假设在磁盘固定位置存储imap,因为imap频繁的被修改,因此会导致频繁的写回磁盘,每当文件修改时,imap也需要随后更新,这会导致额外的seek开销。所以LFS将imap信息和i-node一样存在段中,存在i-node右边,如下图
imap查找问题:imap存储在段中,也出现了i-node查找一样的问题,为了解决这个问题,LFS用一个固定的空间来存放指向imap地址的区域叫作checkpoint region (CR),CR存放了指向最新的imap地址的指针,在查找imap之前会首先加载CR,CR通常是周期性的更新,并不会某一个imap更新就立马写回磁盘
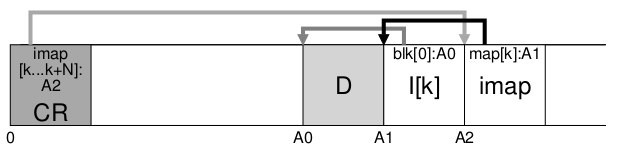
read操作流程,假设此时内存还是空的

目录实现
目录结构:一个目录名映射i-node编号
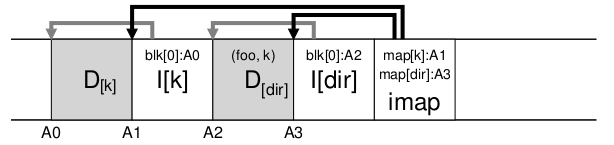
目录存储问题:和i-node一样存在段中,其索引存在段中imap结构中并且缓存在内存中,其结构例子如下,文件foo在目录dir中,通过dir在imap找到存储dir目录的i-node例子中A3,然后在i-nodeA3中找到目录数据在块A2,在A2中查找到foo文件对应k号i-node,然后在imap中查找到k号i-node在A1,最终找到文件foo的数据在块A0中
垃圾回收
垃圾产生的原因
文件更新导致的老的数据块和i-node块无效,如下图
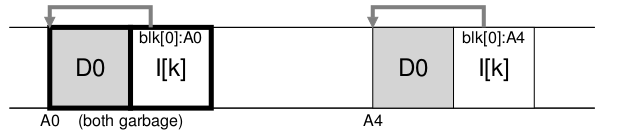
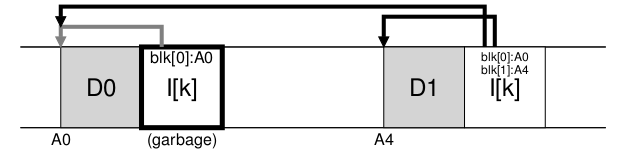
文件增加导致的老的i-node块无效,如下图
垃圾回收流程
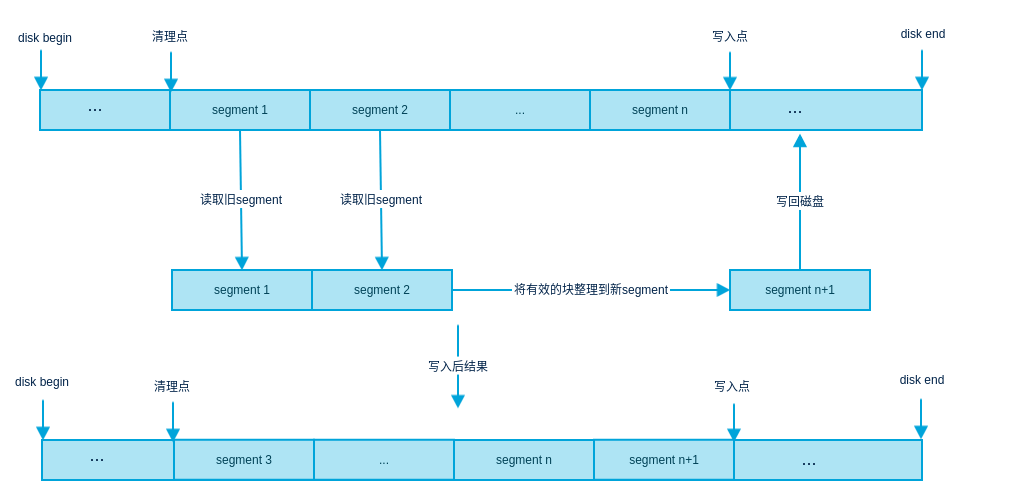
读出旧的段,将段中有效的块复制到内存缓存中,当量达到一个段大小时,像普通修改文件那样以日志方式写入磁盘,旧的段便释放了,下图大概描述了垃圾回收的流程,假设读入segment 1和segment 2然后整理出有效的块并刚好组成一个段,写入磁盘,因此清理点就后移2个段,而写入点后移一个,当写入点达到磁盘最大值时,指针又移到磁盘开始位置,因此在LFS文件系统中,磁盘被抽象成一个大环形数组结构
如何分辨垃圾
前边我们提到过段summary块,这个块主要记录了段内块的摘要信息,每个块所属的i-node和offset。如何确定哪些块是垃圾呢?我们加载段到内存,然后根据段summary信息,查看一个块所属的i-node号,然后从imap中查询最新的i-node存放地址,加载到内存中然后找到offset对应的地址是否为段中块的地址,如果是,那么这个块是活跃的;如果不是那么这个块是垃圾
何时清理
- 定期
- 空闲时
- 磁盘满了,不得不清理
崩溃恢复
保证CR原子写:有两个CR,分布在磁盘两端,交替写入,写入时会先写一个头,里边包含一个时间戳,然后开始写CR body,当写完最后一个块时再写入时间戳,如果是原子写入的,那么两个时间戳是一致的
第一种场景:因为CR是周期性写入,所以可能丢失数据,这种场景解决方式很简单,丢弃最后一个CR后的更新
- 第二种场景:CR的写入不是原子的,解决方式如上述的保证CR原子写的基础上,当系统崩溃时,查找最新一个时间戳一致的CR
总结
LFS是一个优秀的文件系统,它的思想是先进的,并且和现在正逐渐流行的SSD不谋而合。并且它的思想影响非常广,LSM是一个很多存储引擎广泛使用的文件结构,比如BigTable、HBase、Cassandra、LevelDB、SQLite、mangodb3.0的Wired Tiger存储引擎。并且还影响了很多后续的文件系统,比如号称下一代Linux文件系统btrfs、针对NAND SSD的文件系统F2FS,其基础都是LFS,学习LFS对于理解这些很有帮助