背景
由于磁盘的机械特征,导致要想提升它的读写速度是非常困难的。因此SSD应运而生,它的读写速度,因为没有磁头,导致其寻道时间几乎为0。
SSD的分类
- 基于闪存类:采用FLASH芯片作为存储介质,擦写次数有限制
- 基于DRAM的固态硬盘:采用DRAM作为存储介质,它是一种高性能的存储器,而且使用寿命很长,美中不足的是需要独立电源来保护数据安全
针对闪存ssd的特性,虽然其速度快,我们知道大部分的I/O操作都是随机写,如果不仔细的处理,会严重增加I/O的延迟和缩短SSD的寿命。虽然LFS和BTRFS有效的降低了随机写的影响,但是没有完全考虑到SSD的特性(性能和寿命)
F2FS出现了,它是专门为基于 NAND 的存储设备设计的新型文件系统,F2FS是第一个公开提出以优化性能和寿命并且广泛使用的文件系统,下面我们了解F2FS的设计原理
F2FS设计
F2FS磁盘布局示意图
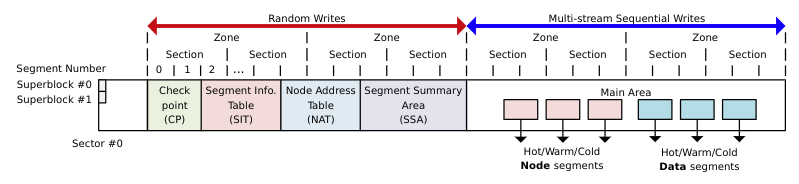
F2FS将磁盘分为三块,super block和随机写区域和顺序写区域,和LFS一样,F2FS也是采用segment来管理磁盘,不过和LFS不同的是,F2FS在段上又加了两层概念,连续的多个segment组成Section,连续多个Section又组成一个Zone
Super Block(SB):超级块,存放F2FS的参数,格式化时写入,不可变
- Check Point(CP):存放文件系统状态,比如空闲空间总量,当前激活segment的摘要信息,CP占用两个segment,但是只有一个是有效的,其存有版本号,只有版本号最高的才是有效的
- Segment Information Table(SIT):记录每个segment的的信息,比如有效块的总数、数据块有效性bitmap,当该segment无有效块时,可以回收
- Node Address Table(NAT):一个记录排序在Main区域的node blocks的块地址表,用于定位所有主区域的索引节点块
- Segment Summary Area(SSA):存储了很多summary项,summary项记录了Main area中块的所有者信息
- Main area:包含两种类型的块,一种是node类型,一种是data类型,node类型存放inode和数据块的索引;data存放目录或文件。注意一个Section中不会存在两种类型的块
一个查找文件的过程
查找过程示意图
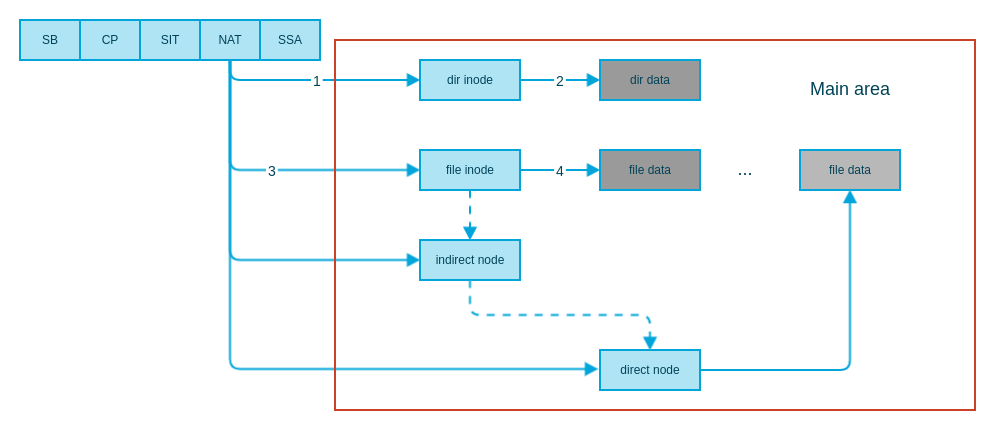
查找过程
- 根据根目录的inode号从NAT中找到inode的块地址
- 在根目录的inode块的数据块中按目录名字查获得目录对应的inode号
- 用目录对应的inode号从NAT中获取真实物理位置
- 然后在目录对应的inode的数据块中找到对应的目录或者文件的inode
- 重复上边第3-4步骤,直到找到对应的文件
文件结构
F2FS文件结构示意图,和前边的LFS和ext结果差不多,F2FS没有ext文件系统的extend树
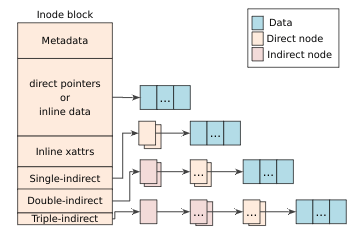
F2FS解决LFS的“wandering tree”
- LFS存在的问题:如果文件的数据块修改之后,间接地址指针块会递归修改
- F2FS解决方案:引入了NAT结构,当数据块修改时,只有直接地址指针块会修改,间接地址块不会修改,因为间接地址块中存放的不是直接地址块的地址,而是存放的NAT项,修改后的直接地址块地址会存入NAT项中,项的索引并不会变。
- F2FS inode可以内联小数据和扩展属性。默认的配置可以存放3,692 bytes,保留200 bytes用于扩展属性。内联可以减小空间开销和提升I/O性能
目录结构
目录块的结构,一个目录块分了bitmap、Reserved、dentries、filename四个区域。dentries中有214个dentry,每个占11byte,最多存储214个取决于文件名字长度;filename区域有214个slot,每个slot8byte,最多存储214个,但是如果有文件名超过8byte,那就需要多个slot存储,那么一个块将不能存储214个目录项
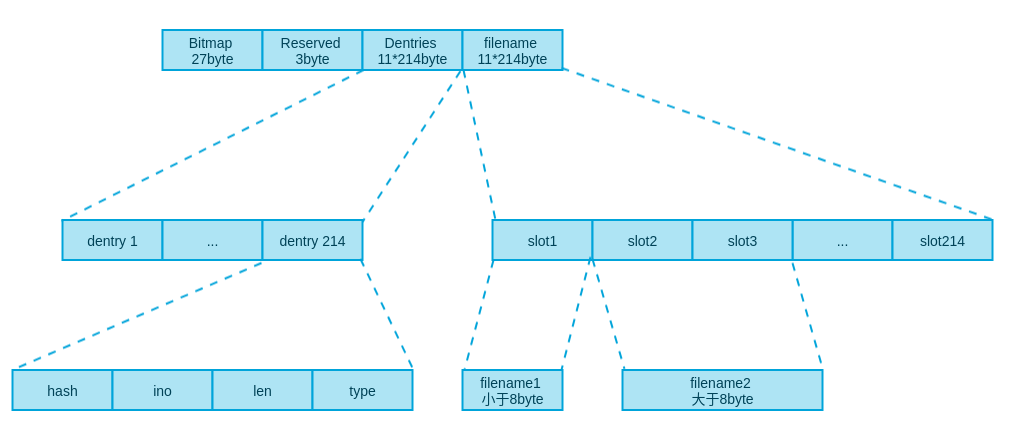
dentry结构如上图,包括hash、ino、len(文件名长度)、type
大目录处理,和所有文件系统一样,一个目录如果含有太多的目录项,那么查询就会变慢。ext采用的hash B-tree,F2FS采用的是多级hash表,示意图如下
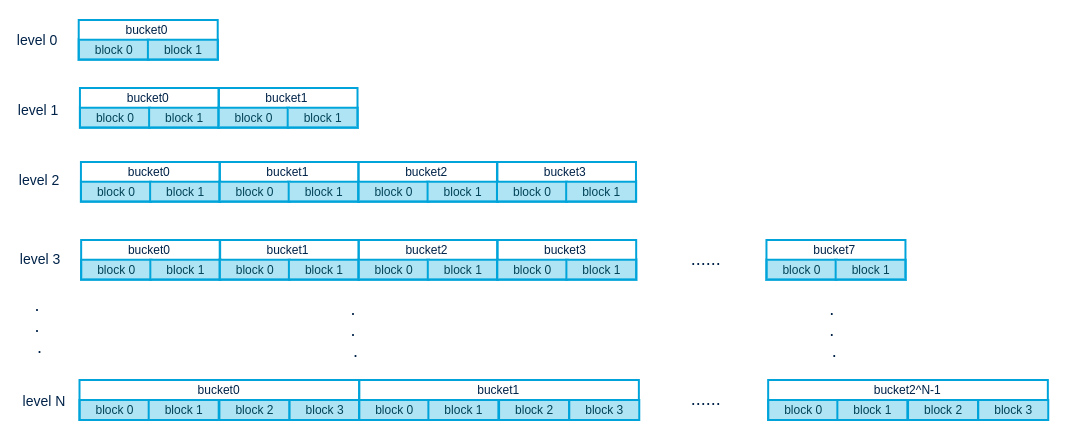
关于每个level的桶里有多少block,有如下公式
每个level有多少桶的公式如下
多日志头
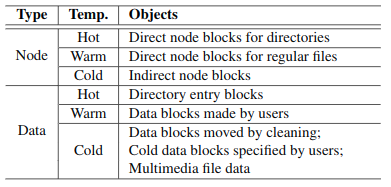
不同于LFS只有一个日志区域,F2FS有六个日志区域,冷数据和热数据写日志是独立的。F2FS分为3个不同的级别温度,冷、暖和热,默认情况下F2FS有六个激活的日志头,级别如下图所示;如果四个激活的日志头,冷和暖数据的node和data类型块;如果两个激活的日志头,一个负责node写入,另一个负责data写入。
清理
- 为了让文件系统有足够的空间,文件系统会不断清理无效空间,清理以selection为单位进行。为了性能考虑,清理分为前台和后台,前台清理是在文件系统空间不足时发生,后台清理是定期进行
- 清理步骤
- 清理selection的选择
- 贪心算法:选择含有最少有效块的selection,前台清理为了低延时选择此算法
- 成本效益算法(cost-benefit):该算法不仅仅取决于有效块的数量,还要考虑selection的年龄,selection的年龄可以由各segment的最后更新时间的平均时间确定。核心思想是,在回收时尽可能回收冷数据,因为热数据可能在接下来的时间还会被更新。后台清理一般采用该算法
- 有效块的识别和迁移
- 快速确定有效块和其父节点块:利用SIT区域保存的segment的有效块bitmap扫描就可以确定哪些块是有效的,SSA区域存放了segment中块的父节点块地址,可以快速找到有效块的父节点进行更新
- 迁移:对于后台清理,并不会立刻迁移有效块,而是将有效块加载到page cache,标记为dirty页,等待回写进程处理,这样即可以减少对其他I/O的影响又可以聚集分散写。
- 清理后续处理:清理后该selection被标记为pre-free状态,当下一个checkpoint建立时,该selection成为真正的free状态,可以再分配。这样处理的原因是,如果在建立checkpoint前将selection设置为free状态,那么可能会被再分配,但是如果此时系统崩溃,恢复时会选择前一个Checkpoint,而在这个checkpoint中该selection还是有效的,这样数据就丢失了。所以一定要在checkpoint建立后再释放selection
- 清理selection的选择
日志写入适配
- LFS提出了两种日志写入策略,normal logging和threaded logging,F2FS也实现了这两种方式
- normal logging:当有足够的空闲空间时,该写入方式很高效,但是当空闲的空间不足时,系统会有很高的清理开销
- threaded logging:当空闲空间不足时,文件系统不进行清理因为此时清理开销很高,并且导致I/O性能严重下降。而是将数据写入dirty segment的无效块上,此时写操作可能变为随机写,因此写性能也有一定程度的下降,但是F2FS根据贪心算法选择segment来尽可能保证连续的无效块来增加顺序写入
- F2FS适配策略,设定一个k,如果有超过k个空闲sections,执行normal logging方式,当空闲sections低于k时,采用threaded logging,k的取值通常为总sections的5%
Checkpointing和Recovery
Checkpointing
Checkpoint区域磁盘结构,原始论文中并没有描述该区域的结构,下图是我根据linux中f2fs的源码和网上资料画的

如上图所示
- CP区域首尾各有一个checkpoint互为备份,其中只有一个是稳定状态,一个是当前使用,一旦出现宕机那么当前正在使用的checkpoint将无效,会利用稳定版本来恢复文件系统
- 通常checkpoint不足一个块,接下来是sit/nat version bitmap,为了文件系统安全稳定,sit和nat有两个副本,该bitmap标记哪个副本是最新的。sit/nat version bitmap如果很小那么就和checkpoint存在一个块中,如果太大就会存入下一个块中
- 然后是Orphan inode
- 接下来是激活segments的摘要信息
- 最后是另一个checkpoint结尾
Checkpointing触发条件:sync、umount和前台清理
Checkpointing执行步骤
- 刷新所有node和数据块的页缓存
- 挂起系统写操作,比如create、unlink和mkdir
- 将文件系统元数据写回磁盘,比如NAT、SIT和SSA
- 更新checkpoint的状态,包括以下内容
- 首尾各一个checkpoint
- NAT和SIT bitmaps:指示当前checkpoint正在使用的NAT和SIT块
- NAT和SIT journals:NAT和SIT的日志
- 激活segments的摘要信息
- Orphan blocks:保存Orphan inode(一个inode在关闭之前删除,比如两个进程在使用同一个文件,而其中一个进程删除了该文件,该文件的inode就会被注册为orphan inode),因此F2FS可以在宕机启动后恢复该inode
回滚恢复操作
- 选择最新的稳定版本checkpoint
- 判断orphan inode block是否存在,如果存在,就清空orphan inode对应的数据块,然后释放orphan inode
- 然后根据cp的sit/nat version bitmap恢复元数据和构建映射表
前滚恢复操作,为了实现该操作,需要在direct node上加一个标记位,当文件系统前滚恢复时,可以根据这些标记位来重建这些更新数据块的索引
- 完成后滚恢复操作
- F2FS收集了日志位置是N+n的,含有特殊标记位的direct node block,用一个list来存储这些node信息,其中n表示在上一次稳定的Checkpoint写入后更新的块数目。
- 根据list中的node信息,文件系统将距离上一次稳定的Checkpoint最靠近的被更新的node blocks(日志位置是N-n),载入到page cache中。
- 比较日志位置是N-n和N+n的数据索引是否一致,如果不一致则使用N+n的数据覆盖已经缓存的N-n的node block,然后标记为脏。
- 最后执行Checkpoint流程,刷新元数据
总结
F2FS由三星工程师开发,但是一开始三星并没有采用,而是将其开源,借助开源社区的力量来优化改进。后来经过华为优化后用于手机使用,不过后来华为又采用EROFS。F2FS相对于ext3/4,对于4K左右的细碎小文件,有非常明显的读写速度提升,更多详情参考一下参考资料。