引言
最近忙着找工作,都没时间更新,今天忽然有点想法,想写一篇关于缓存的文章,仅仅是自己的一点看法。
如果说到缓存,大家可能会想到CPU的高速缓存、Redis、MemCached,还有自己实现的单机本地缓存,它们的作用其实都是一个,那就是方便我们的应用可以更快的获得我们需要的数据。
在远古计算机时代,计算机CPU的速度很慢,存储设备的速度也很慢,所以这个时候我们可能都用不上缓存,因为没必要嘛,CPU速度和存储设备的速度一致。
随着技术的发展,CPU由晶体管发展成超大规模集成电路使得cpu的发展发生了质变,cpu的速度越来越快。而存储设备虽然也有快速的发展,但是在速度上却没有质变。这里我们做一个假设,如果存储器设备的速度跟的上CPU的运行速度,那我们还需要缓存吗?当然不需要,因为如果速度还是一致的,那肯定是CPU直接访问存储设备,这样的架构是简单的架构。但是事实却不是这样,至少目前不是这样,当然不排除未来有什么特殊材料实现的存储设备拥有和cpu匹配的速度。因此从计算机的发展来看,缓存是为了存储设备的速度能够匹配CPU速度的一种折中方案。因为出现了内存,后来的CPU缓存,更后来的CPU多级缓存,它们的速度都是越来越快,当然容量也越来越小。
上一段提到内存其实是磁盘的缓存,cpu高速缓存是内存的缓存。所以这里有一个推论,那就是高级的存储设备是低级存储设备的缓存。还有一个特点,高级存储设备容量小,低级存储设备容量更大,所以我们不能把所有数据都存储更高层次的缓存中,这就诞生了今天我们常用的一些缓存淘汰算法,针对内存来说就是页面置换算法,本质上其实是一个东西。我们在学习的过程中要多看,才能在更高的层次上看待一个技术,并且需要结合它出现的背景,这样才能理解它是用来解决什么问题,才能看到技术的本质,因为技术就是用来解决问题的。
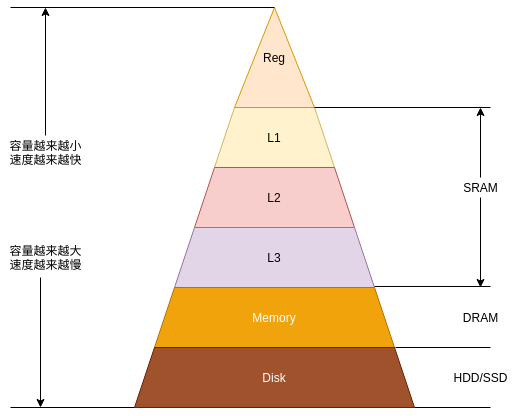
存储设备层次抽象
前边提到,高层次的存储设备是低层次存储设备的缓存,下图是一个存储设备层次抽象的示意图
磁盘
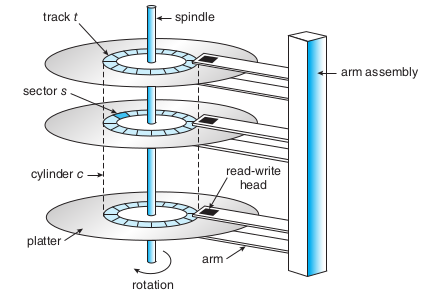
磁盘(HDD)是一种机械设备,它包括磁盘片、磁头还有电机带动的转轴结构如下图,这也使得磁盘的读取速度永远跟不上CPU的速度,这是机械装置和电子设备的差异,HDD的速度主要取决于转速、移动磁头的延迟。磁盘还有很多其他的特性,这里不会做展开介绍,这里只是想介绍存储设备的抽象层级,便于我们理解缓存。磁盘的容量都比较大,目前1T、2T的磁盘都是非常普遍的也是通用的持久化存储的存储设备。
不过近些年SSD变得流行,不过在短期内完全取代HDD的可能性还是比较小。不同与HDD,SSD其内部构造是电子设备的构造,所以在读写速度上是比HDD的,至于快多少,这个要取决是SSD使用的技术和接口,因为SATA接口也就是HDD的接口其速度是小于PCIe的接口。
主存
主存是一种易失性的存储设备,属于DRAM,一旦漏电数据丢失,一般10-100ms,系统必须周期性的刷新重写内存每一位,因此一旦断电,那么数据就会丢失,主存的容量是远远小于磁盘的容量,目前普通的单张内存条在8~32G之间,其主频目前主要在1333~4000+,主存的速度主要取决与其主频,因此主频越高,速度越快。
高速缓存
高速缓存也是一种易失性的存储设备,不过和主存不同,它们主要是SRAM,只要有电,它就会永远保存它的值,它的访问时间比DRAM快,但是其造价远高于DRAM,这也就限制了SRAM不能做得很大,因此一般用来做高速缓存。
CPU的高速缓存在现代处理器中分为了三级。其中一级缓存是最快的,当然其容量也是最小的通常以KB记,比如我的电脑是64KB,32KB的数据缓存,32KB的指令缓存;二级缓存为256KB,通常一级缓存和二级缓存都是cpu核心独享的;三级缓存为10MB,通常为整个cpu的所有核心共享。Linux下可以通过lscpu命令查看自己电脑的CPU缓存信息
寄存器
寄存器是最快的存储设备,其速度一般要和cpu时钟周期匹配,一般情况下对寄存器的访问要在半个cpu时钟周期内完成,它的容量非常小,以字节为单位,通常情况下32位CPU为4个字节,64位CPU为8个字节。
缓存淘汰算法
从上边我们看出了高层次的存储器是低层次存储器的缓存,但是高层次的存储器有容量小的限制,因此不可能把所有的数据缓存到高层次存储器中,所以很容易想到的,把我们需要用到的数据放进去就行了。核心思想是这样的,因为程序运行时只有少部分数据是当前需要的,这里又出现一个问题,当高层次存储器已满,需要的数据不在存储器中时,需要选择一些数据逐出到低层次存储器,把需要的数据交换进来,由此可见缓存是一个见利忘义的家伙。这个贪心的家伙要想把利益最大化,因此有了后来的很多缓存淘汰算法,不管是什么缓存,这一些算法的思想都是一样的。接下来,介绍其中一些比较常用的算法
FIFO
- 定义:FIFO表示是先近先出,这是一种最简单的方式,核心思想是当缓存空间不足时选择,最先进入的数据逐出缓存,给新的数据腾出空间
- 实现:实现也非常简单,只需要用一个单向链表记录加入缓存的顺序就可以了,采用尾插法,缓存空间不足时淘汰head节点
- 缺点:缺点非常明显,没有考虑到程序运行时,数据的局部性,也就是说程序运行过程中,只有少部分的数据是频繁访问的
LRU
定义:LRU指最近最少使用,它的核心思想是,如果一个数据最近都没有使用过,那么在之后的一段时间内也不会使用,因此当缓存不足时,会将它逐出。
实现:实现的方式有很多,这里介绍一种链表的实现方式,这种实现可以让插入节点和淘汰节点的时间复杂度为$O(1)$,当然查找算法因为不在这一次讨论的范围就不做多介绍,这里可以用hash结构来加速查找速度,未来会专门写一篇来介绍关于查找的文章
假设缓存可以缓存4个数据,加载的顺序为1,2,3,4,新节点或被访问过的节点都会插入或移动到tail

假设节点2被访问,那么其变化如下图

假设此时需要加载5进缓存,因为空间不足,所以需要淘汰掉最近最少使用的数据,那么就是head节点

缺点:想象一下,如果我们正在分块遍历一个大文件,如果按照LRU的算法,会发生什么事?一个结果是这个文件很大的时候,会把我们其他缓存全部逐出,但是遍历这个大文件我们可能只做一次,那这一次不是亏大了,我们之前的热点数据全部需要重新加载一遍。
改进:针对这个缺点有什么改进的方法呢?我们知道程序运行只有少部分的数据是热点数据,大部分的数据生命周期都是比较短暂的,因为可以效仿JVM对java对象的管理方式,采用分代的理念来管理缓存。可以将缓存的链表分割为两部分,新生代和老年代(叫什么并不重要,重要的数据要区分管理)。我们假设当数据进入缓存时,首先进入新生代,它每次被访问会增加一代,当它的代数达到设定的阈值后那就进入老年代,这样像上边提到的那种访问大文件的情况就会被过滤掉
假设初始的状态如下图

假设现在要加入数据10,那么新生代空间不足,那么要淘汰没有晋升的head节点

假设现在10被多次访问达到了晋升的阈值,那么它进入老年代的链表,插入old_tail,如果空间不足,淘汰old_head

LFU
定义:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。需要记录数据的访问频次,这里我们可以采用hash的结构用次数作为key,其结构如下图,插入时采用头插入,因此在选择淘汰节点时,选择尾步节点,这样相同访问频次的节点可以淘汰访问时间最远的
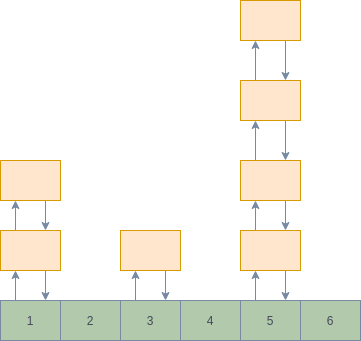
缺点:仅考虑频次,那样先进入缓存的数据有频次上的优势
改进:可以引入一个衰减因子来处理那些长时间没有访问的节点,降低它的频次,这样就可以使存储在缓存中的数据是热点数据
总结
本文章只是随想,当然缓存算法不仅仅是这些。迁移学习是一个非常重要的能力,不管是什么缓存,本质都是一样的。